假设我有一个csv文件,我想使用pyplot和pandas在Python中导入并绘制图表。
1,2
2,4
3,3
4,4
5,6
6,3
7,5
8,6
1,3
2,5
3,7
4,4
5,3
6,5
7,4
8,5
1,3
2,2
3,5
4,4
5,3
6,5
7,6
8,7
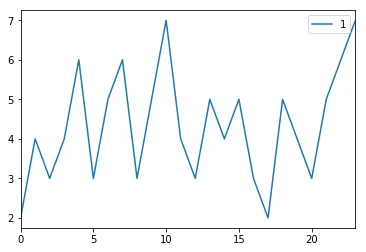
正如您所见,第一列在数字8处翻转。我该如何消除这种翻转现象,使其看起来像这样:
1,2
2,4
3,3
4,4
5,6
6,3
7,5
8,6
9,3
10,5
11,7
12,4
13,3
14,5
15,4
16,5
17,3
18,2
19,5
20,4
21,3
22,5
23,6
24,7
我尝试使用for循环搜索整个列,并记录每次发现一个比上一个数字小的数字……这必须是一个溢出!我正在遍历整个数据集(其中有95,000个元素!),当我看到当前项目大于上一个项目时,我将其乘以一个计数器……当这样做错误时,计数器会递增,然后加到当前条目中,直到检测到另一个溢出。 但是,我做错了什么,我不确定是什么...我的索引在两端出现问题.. Pythonic的方法是如何搜索这个混乱的数据?
pd.read_csv('data.csv', usecols=[1])- Gerges