如何以最佳方式(指传统方式)检查列表中的所有元素是否唯一?
我目前使用Counter的方法是:
>>> x = [1, 1, 1, 2, 3, 4, 5, 6, 2]
>>> counter = Counter(x)
>>> for values in counter.itervalues():
if values > 1:
# do something
虽然不是最有效的方法,但它直接简洁:
if len(x) > len(set(x)):
pass # do something
对于短列表可能不会有太大的影响。
以下是一个两行代码的示例,还能实现早期退出:
>>> def allUnique(x):
... seen = set()
... return not any(i in seen or seen.add(i) for i in x)
...
>>> allUnique("ABCDEF")
True
>>> allUnique("ABACDEF")
False
如果x的元素不可哈希,那么你将不得不使用一个列表来代替seen:
>>> def allUnique(x):
... seen = list()
... return not any(i in seen or seen.append(i) for i in x)
...
>>> allUnique([list("ABC"), list("DEF")])
True
>>> allUnique([list("ABC"), list("DEF"), list("ABC")])
False
一个早期退出的解决方案可能是
def unique_values(g):
s = set()
for x in g:
if x in s: return False
s.add(x)
return True
然而,对于小规模的情况或者如果提前退出不是常见情况,那么我会期望 len(x) != len(set(x)) 是最快的方法。
s = set()之后添加以下行来缩短代码... return not any(s.add(x) if x not in s else True for x in g)。 - Andrew Clarklen(x) != len(set(x)) 比这个更快吗?难道两个操作都是 O(len(x)) 吗?(其中 x 是原始列表) - Chris Redfordif x in s。 - Chris Redford为了速度:
import numpy as np
x = [1, 1, 1, 2, 3, 4, 5, 6, 2]
np.unique(x).size == len(x)
把所有条目添加到一个集合中,然后检查它的长度如何?
len(set(x)) == len(x)
len()。 - PaulMcG除了使用 set,您还可以使用 dict。
len({}.fromkeys(x)) == len(x)
我已经将建议的解决方案与perfplot进行了比较,发现
len(lst) == len(set(lst))
如果列表中存在早期重复项,则确实是最快的解决方案。有一些常量时间的解决方案更值得推荐。
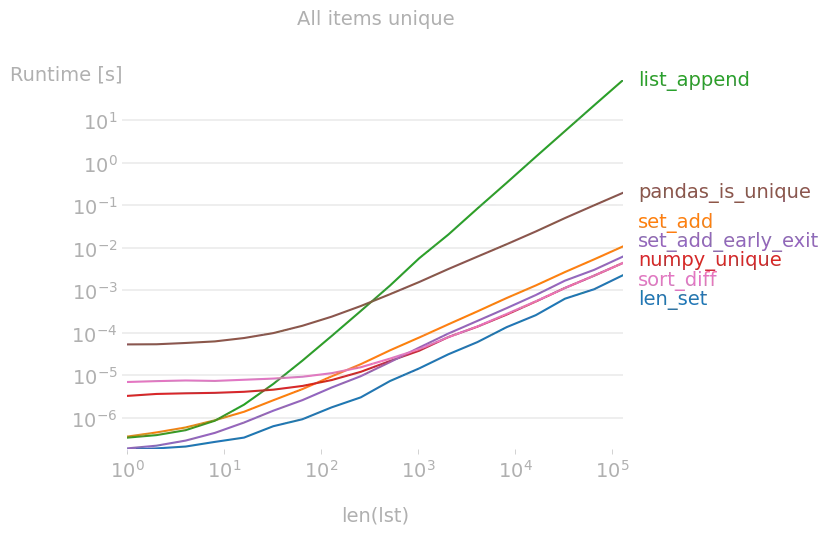
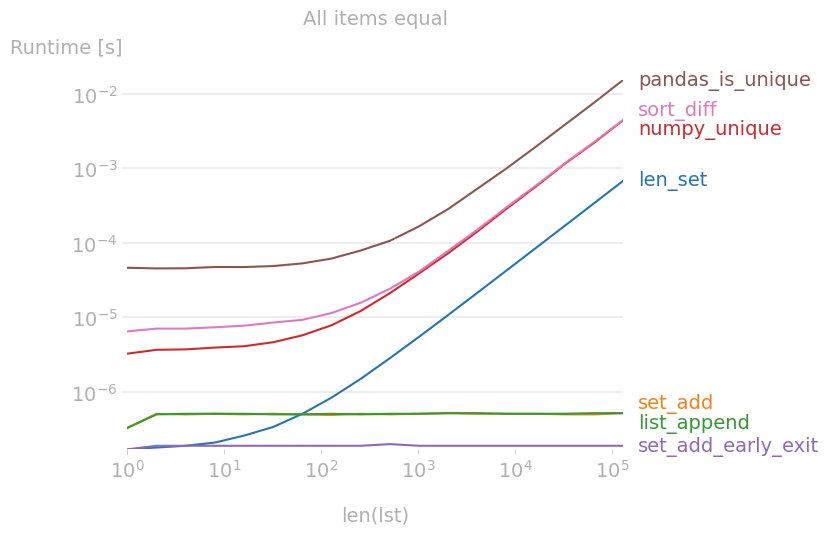
复制绘图的代码:
import perfplot
import numpy as np
import pandas as pd
def len_set(lst):
return len(lst) == len(set(lst))
def set_add(lst):
seen = set()
return not any(i in seen or seen.add(i) for i in lst)
def list_append(lst):
seen = list()
return not any(i in seen or seen.append(i) for i in lst)
def numpy_unique(lst):
return np.unique(lst).size == len(lst)
def set_add_early_exit(lst):
s = set()
for item in lst:
if item in s:
return False
s.add(item)
return True
def pandas_is_unique(lst):
return pd.Series(lst).is_unique
def sort_diff(lst):
return not np.any(np.diff(np.sort(lst)) == 0)
b = perfplot.bench(
setup=lambda n: list(np.arange(n)),
title="All items unique",
# setup=lambda n: [0] * n,
# title="All items equal",
kernels=[
len_set,
set_add,
list_append,
numpy_unique,
set_add_early_exit,
pandas_is_unique,
sort_diff,
],
n_range=[2**k for k in range(18)],
xlabel="len(lst)",
)
b.save("out.png")
b.show()
另一种完全不同的方法是使用sorted和groupby:
from itertools import groupby
is_unique = lambda seq: all(sum(1 for _ in x[1])==1 for x in groupby(sorted(seq)))
这需要进行排序,但在第一个重复值出现时就退出。
groupby的解决方案并找到了这个答案。我认为这是最优雅的,因为它是一个单一的表达式,并且可以使用内置工具而不需要任何额外的变量或循环语句。 - Lars Blumbergid()函数对它们进行排序,因为这是groupby()正常工作的先决条件:groupby(sorted(seq), key=id)。 - Lars Blumberg以下是一个递归的 O(N2) 版本代码,仅供娱乐:
def is_unique(lst):
if len(lst) > 1:
return is_unique(s[1:]) and (s[0] not in s[1:])
return True
这里是一个递归的提前退出函数:
def distinct(L):
if len(L) == 2:
return L[0] != L[1]
H = L[0]
T = L[1:]
if (H in T):
return False
else:
return distinct(T)
在不使用奇怪(缓慢)的转换方式且采用函数式方法下,速度已经足够快。
H in T 进行线性搜索,而 T = L[1:] 复制了列表的切片部分,因此在大型列表上,这将比其他已提出的解决方案慢得多。我认为它是 O(N^2),而大多数其他解决方案是 O(N)(集合)或 O(N log N)(基于排序的解决方案)。 - Blckknght
x中的元素不唯一时,len(x)> len(set(x))为真。这个问题的标题恰恰相反:“检查列表中所有元素是否都是唯一的”。 - WhyWhat