我需要一个函数,输入一个 list ,如果全部元素在使用标准等号操作符进行比较时相等,则输出True ,否则输出False 。
我认为最好的方法是通过迭代列表并比较相邻元素,然后使用AND 运算符组合所有的布尔值。但我不确定最Pythonic的方式是什么。
我需要一个函数,输入一个 list ,如果全部元素在使用标准等号操作符进行比较时相等,则输出True ,否则输出False 。
我认为最好的方法是通过迭代列表并比较相邻元素,然后使用AND 运算符组合所有的布尔值。但我不确定最Pythonic的方式是什么。
itertools.groupby(请参阅itertools recipes):from itertools import groupby
def all_equal(iterable):
g = groupby(iterable)
return next(g, True) and not next(g, False)
或者不使用 groupby:
def all_equal(iterator):
iterator = iter(iterator)
try:
first = next(iterator)
except StopIteration:
return True
return all(first == x for x in iterator)
有一些备选的单行代码可以考虑:
Converting the input to a set and checking that it only has one or zero (in case the input is empty) items
def all_equal2(iterator):
return len(set(iterator)) <= 1
Comparing against the input list without the first item
def all_equal3(lst):
return lst[:-1] == lst[1:]
Counting how many times the first item appears in the list
def all_equal_ivo(lst):
return not lst or lst.count(lst[0]) == len(lst)
Comparing against a list of the first element repeated
def all_equal_6502(lst):
return not lst or [lst[0]]*len(lst) == lst
但是它们也有一些缺点,包括:
all_equal 和 all_equal2 可以使用任何迭代器,但其他函数必须采用序列输入,通常是像列表或元组这样的具体容器。all_equal 和 all_equal3 一旦发现差异就会停止(称为 "short circuit"),而所有其他替代方法都需要遍历整个列表,即使您可以通过查看前两个元素就知道答案是 False。all_equal2 中,内容必须是 hashable。例如,一个列表的列表将引发 TypeError。all_equal2(在最坏的情况下)和 all_equal_6502 创建了列表的副本,这意味着您需要使用双倍的内存。在 Python 3.9 上,使用 perfplot,我们得到以下时间(较低的 Runtime [s] 值更好):
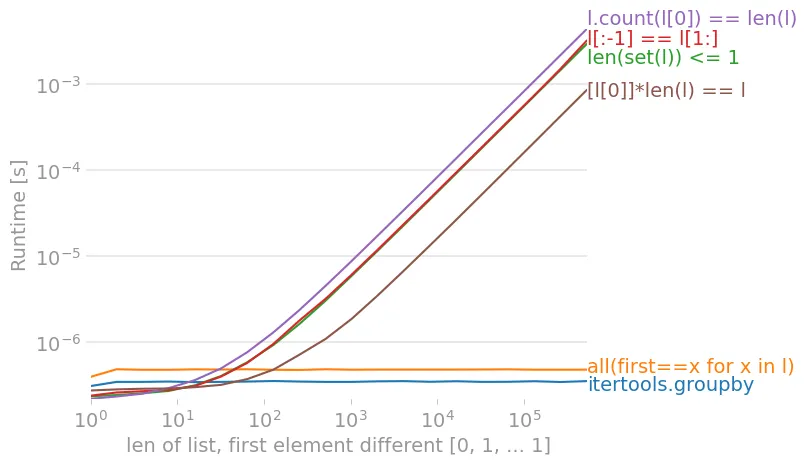
![for a list with no differences, count(l[0]) is fastest](https://istack.dev59.com/jLwdT.webp)
obj.__eq__的调用,并且可以进行乱序优化以更快地允许对排序列表进行短路处理。 - Glenn Maynardfirst == second and second == third and ... 时,所有项目都是相同的。 - teichertall_equal 中,您可以使用 first = next(iterator, None) 来避免 try/except 结构。 - Stanislav Volodarskiy一个比使用set()更快的解决方案是对序列(而不是可迭代对象)的第一个元素进行计数。这假设列表非空(但这很容易检查,你可以自行决定在空列表上的结果应该是什么)。
x.count(x[0]) == len(x)
一些简单的基准测试:
>>> timeit.timeit('len(set(s1))<=1', 's1=[1]*5000', number=10000)
1.4383411407470703
>>> timeit.timeit('len(set(s1))<=1', 's1=[1]*4999+[2]', number=10000)
1.4765670299530029
>>> timeit.timeit('s1.count(s1[0])==len(s1)', 's1=[1]*5000', number=10000)
0.26274609565734863
>>> timeit.timeit('s1.count(s1[0])==len(s1)', 's1=[1]*4999+[2]', number=10000)
0.25654196739196777
count方法,而非迭代器为什么没有提供len方法。答案可能是因为这只是一个疏忽。但对我们来说无关紧要,因为序列的默认.count()方法非常慢(纯Python)。你的解决方案之所以如此快速,是因为它依赖于由list提供的C语言实现的count方法。因此,我想无论哪个可迭代对象在C中实现了count方法,都能从你的方法中受益。 - maxtimeit.timeit('all(i == s1[0] for i in set(s1))', 's1=[1]*5000', number=10000)。在我的系统上,它的时间为0.39毫秒,而count==len则需要0.16毫秒。 - Aaron3468[编辑:此答案回答了目前得票最高的itertools.groupby(这是一个很好的答案)后来的答案。]
在不重写程序的情况下,最渐进性能最佳且最易读的方法如下:
all(x==myList[0] for x in myList)
(没错,即使是空列表也能运行!这是因为在这种情况下,Python采用了惰性语义之一。)
这个方法会在最早的时间点失败,所以渐进优化了(期望时间复杂度约为O(#uniques),而不是O(N),但最坏情况下仍然是O(N))。假设你以前没有见过这些数据......
(如果你关心性能但并非非常关心,你可以首先进行通常的标准优化,例如提升 myList[0] 常量出循环并为边缘情况添加笨重的逻辑,尽管这是Python编译器可能最终学会如何做的事情,因此除非绝对必要,否则不应该这么做,因为它会破坏可读性而获得最小的收益。)
如果你更关心性能,那么以下代码比上面的快两倍,但有点冗长:
def allEqual(iterable):
iterator = iter(iterable)
try:
firstItem = next(iterator)
except StopIteration:
return True
for x in iterator:
if x!=firstItem:
return False
return True
itertools.groupby答案,其速度是allEqual的两倍,因为它可能是经过优化的C代码。根据文档,它应该(类似于此答案)没有任何内存开销,因为惰性生成器永远不会被评估为列表...虽然这可能让人担心,但伪代码显示分组的“列表”实际上是惰性生成器。.isAllEqual(),并只需检查它是否符合{something:someCount}的形式,即len(counter.keys())==1;或者在单独的变量中保留计数器。这可证明比任何其他方法都要好,直到常数因子。也许您还可以使用Python的FFI和ctypes以您选择的方式进行处理,也可以使用启发式(例如,如果它是具有getitem的序列,则首先检查第一个元素,最后一个元素,然后按顺序检查元素)。checkEqual1慢了一点(1.5倍)。我不确定为什么。 - maxfirst=myList[0] all(x==first for x in myList),所以出现了这种情况。 - ninjagecko>>> timeit.timeit('all([y == x[0] for y in x])', 'x=[1] * 4000', number=10000)
2.707076672740641
>>> timeit.timeit('x0 = x[0]; all([y == x0 for y in x])', 'x=[1] * 4000', number=10000)
2.0908854261426484 - Matt Libertyfirst=myList[0]在空列表上会抛出IndexError异常,因此那些谈论我提到的优化的评论者们将不得不处理空列表的边界情况。不过原始代码是没问题的(x==myList[0]在all函数内部是没问题的,因为如果列表为空,则不会对其进行求值)。 - ninjageckoif len(set(input_list)) == 1:
# input_list has all identical elements.
False,但实际上应该返回 True。此外,它要求所有元素都是可哈希的。 - user3064538说句实话,在最近的python-ideas邮件列表中出现了这个问题。结果证明已经有一个迭代器配方可以完成这个任务:1
def all_equal(iterable):
"Returns True if all the elements are equal to each other"
g = groupby(iterable)
return next(g, True) and not next(g, False)
据说它的性能非常好,并且具有一些不错的特性。
1换句话说,我不能为想出解决方案而得到荣誉,甚至不能为发现它而得到荣誉。
return next(g, f := next(g, g)) == f(来自py3.8) - Chris_Rands这是一个简单的方法:
result = mylist and all(mylist[0] == elem for elem in mylist)
这略微复杂,会产生函数调用开销,但语义更清晰明了:
def all_identical(seq):
if not seq:
# empty list is False.
return False
first = seq[0]
return all(first == elem for elem in seq)
for elem in mylist[1:] 来避免这里的冗余比较。虽然我猜测 elem[0] is elem[0],因此解释器可能可以非常快速地进行比较,但我怀疑它并没有显著提高速度。 - Brendan这是另一个选项,对于长列表比len(set(x))==1更快(使用短路)
def constantList(x):
return x and [x[0]]*len(x) == x
检查数组中的所有元素是否等于第一个元素。
np.allclose(array, array[0])
关于使用 reduce() 和 lambda。这里是一份工作代码,我认为比其他答案好得多。
reduce(lambda x, y: (x[1]==y, y), [2, 2, 2], (True, 2))
返回一个元组,其中第一个值是布尔值,表示所有项是否相同。
[1, 2, 2]):它没有考虑先前的布尔值。这可以通过将x [1] == y替换为x [0] and x [1] == y来修复。 - schot
a == b,相同即为a is b。 - kennytmfunctools.reduce(operator.eq, a)没有被建议。 - user2846495functools.reduce(operator.eq, a)不能正常工作。例如,对于列表[True,False,False],它将返回((True == False) == False),这是True。而函数应该返回False(因为元素并不全部相等)。 - Nephanth