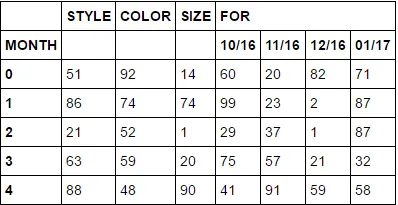
我有一些按月份分组的预测数据。 原始数据框架长这个样子:something
>>clean_table_grouped[0:5]
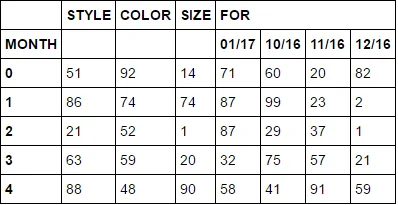
STYLE COLOR SIZE FOR
MONTH 01/17 10/16 11/16 12/16
0 ####### ###### #### 0.0 15.0 15.0 15.0
1 ####### ###### #### 0.0 15.0 15.0 15.0
2 ####### ###### #### 0.0 15.0 15.0 15.0
3 ####### ###### #### 0.0 15.0 15.0 15.0
4 ####### ###### #### 0.0 15.0 15.0 15.0
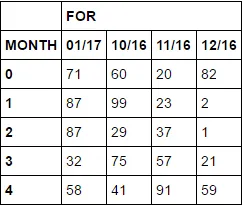
>>clean_table_grouped.ix[0:,"FOR"][0:5]
MONTH 01/17 10/16 11/16 12/16
0 0.0 15.0 15.0 15.0
1 0.0 15.0 15.0 15.0
2 0.0 15.0 15.0 15.0
3 0.0 15.0 15.0 15.0
4 0.0 15.0 15.0 15.0
我只想按照以下方式重新排列这4列:
(保持数据框的其他部分不变)
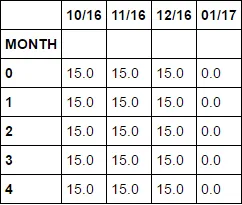
MONTH 10/16 11/16 12/16 01/17
0 15.0 15.0 15.0 0.0
1 15.0 15.0 15.0 0.0
2 15.0 15.0 15.0 0.0
3 15.0 15.0 15.0 0.0
4 15.0 15.0 15.0 0.0
我的尝试解决方案是按照下面的帖子重新排列子集的列: 如何更改DataFrame列的顺序?
我通过获取列列表并首先进行排序来完成此操作。
>>for_cols = clean_table_grouped.ix[:,"FOR"].columns.tolist()
>>for_cols.sort(key = lambda x: x[0:2]) #sort by month ascending
>>for_cols.sort(key = lambda x: x[-2:]) #then sort by year ascending
查询数据框运行良好
>>clean_table_grouped.ix[0:,"FOR"][for_cols]
MONTH 10/16 11/16 12/16 01/17
0 15.0 15.0 15.0 0.0
1 15.0 15.0 15.0 0.0
2 15.0 15.0 15.0 0.0
3 15.0 15.0 15.0 0.0
4 15.0 15.0 15.0 0.0
然而,当我尝试在原始表中设置值时,我得到了一个“NaN”的表格:
>>clean_table_grouped.ix[0:,"FOR"] = clean_table_grouped.ix[0:,"FOR"][for_cols]
>>clean_table_grouped.ix[0:,"FOR"]
MONTH 01/17 10/16 11/16 12/16
0 NaN NaN NaN NaN
1 NaN NaN NaN NaN
2 NaN NaN NaN NaN
3 NaN NaN NaN NaN
4 NaN NaN NaN NaN
5 NaN NaN NaN NaN
我还尝试了压缩以避免链接语法(.ix [] [])。 这样可以避免NaN,但是它不会改变数据框架-__-
>>for_cols = zip(["FOR", "FOR", "FOR", "FOR"], for_cols)
>>clean_table_grouped.ix[0:,"FOR"] = clean_table_grouped.ix[0:,for_cols]
>>clean_table_grouped.ix[0:,"FOR"]
MONTH 01/17 10/16 11/16 12/16
0 0.0 15.0 15.0 15.0
1 0.0 15.0 15.0 15.0
2 0.0 15.0 15.0 15.0
3 0.0 15.0 15.0 15.0
4 0.0 15.0 15.0 15.0
我意识到我正在使用ix重新分配值。然而,我曾经在非分组的数据帧上使用过这种技术,并且它已经完美地工作了。
如果这个问题已经在另一个帖子中得到了回答(以清晰的方式),请提供链接。我搜索过了,但没有找到类似的内容。
编辑: 我已经找到了解决方案。通过创建一个新的多索引数据帧来手动重新索引,以您想要排序的顺序。我在下面发布了解决方案。