我正在尝试使用
下面的代码生成所需的树:
以下代码生成了终端图,但是终端节点上没有期望的标签:
如果我能显示节点的平均y值,那么很容易就可以用百分位数来增强标签,因此我的第一步是仅在每个终端节点上方显示其平均y值。
我知道可以使用以下代码检索节点(此处为节点#12)内的平均y值:
但是看起来这是正确的方法,因为如果我使用:
partykit绘制由rpart生成的回归树。假设使用的公式为y ~ x1 + x2 + x3 +...+ xn。我想要实现的是,终端节点上有箱线图,并在顶部列出分配给每个节点的观测值y的分布的第10、50和90个百分位数的标签,即,在表示每个终端节点的箱线图上方,我想显示一个标签,如“第10百分位数=$200,平均值=$247,第90百分位数=$292。”下面的代码生成所需的树:
library("rpart")
fit <- rpart(Price ~ Mileage + Type + Country, cu.summary)
library("partykit")
tree.2 <- as.party(fit)
以下代码生成了终端图,但是终端节点上没有期望的标签:
plot(tree.2, type = "simple", terminal_panel = node_boxplot(tree.2,
col = "black", fill = "lightgray", width = 0.5, yscale = NULL,
ylines = 3, cex = 0.5, id = TRUE))
如果我能显示节点的平均y值,那么很容易就可以用百分位数来增强标签,因此我的第一步是仅在每个终端节点上方显示其平均y值。
我知道可以使用以下代码检索节点(此处为节点#12)内的平均y值:
colMeans(tree.2[12]$fitted[2])
我尝试创建一个公式,并使用boxplot面板生成函数的 mainlab 参数来生成包含此平均值的标签:
labf <- function(node) colMeans(node$fitted[2])
plot(tree.2, type = "simple", terminal_panel = node_boxplot(tree.2,
col = "black", fill = "lightgray", width = 0.5, yscale = NULL,
ylines = 3, cex = 0.5, id = TRUE, mainlab = tf))
很遗憾,这会生成错误消息:
Error in mainlab(names(obj)[nid], sum(wn)) : unused argument (sum(wn)).
但是看起来这是正确的方法,因为如果我使用:
plot(tree.2, type = "simple", terminal_panel = node_boxplot(tree.2,
col = "black", fill = "lightgray", width = 0.5, yscale = NULL,
ylines = 3, cex = 0.5, id = TRUE, mainlab = colMeans(tree.2$fitted[2])))
然后我在根节点处显示了正确的平均y值。我希望能帮助修复上述错误,以便我可以显示每个单独终端节点的平均y值。从那里开始,添加其他百分位数并使格式变得漂亮应该很容易。
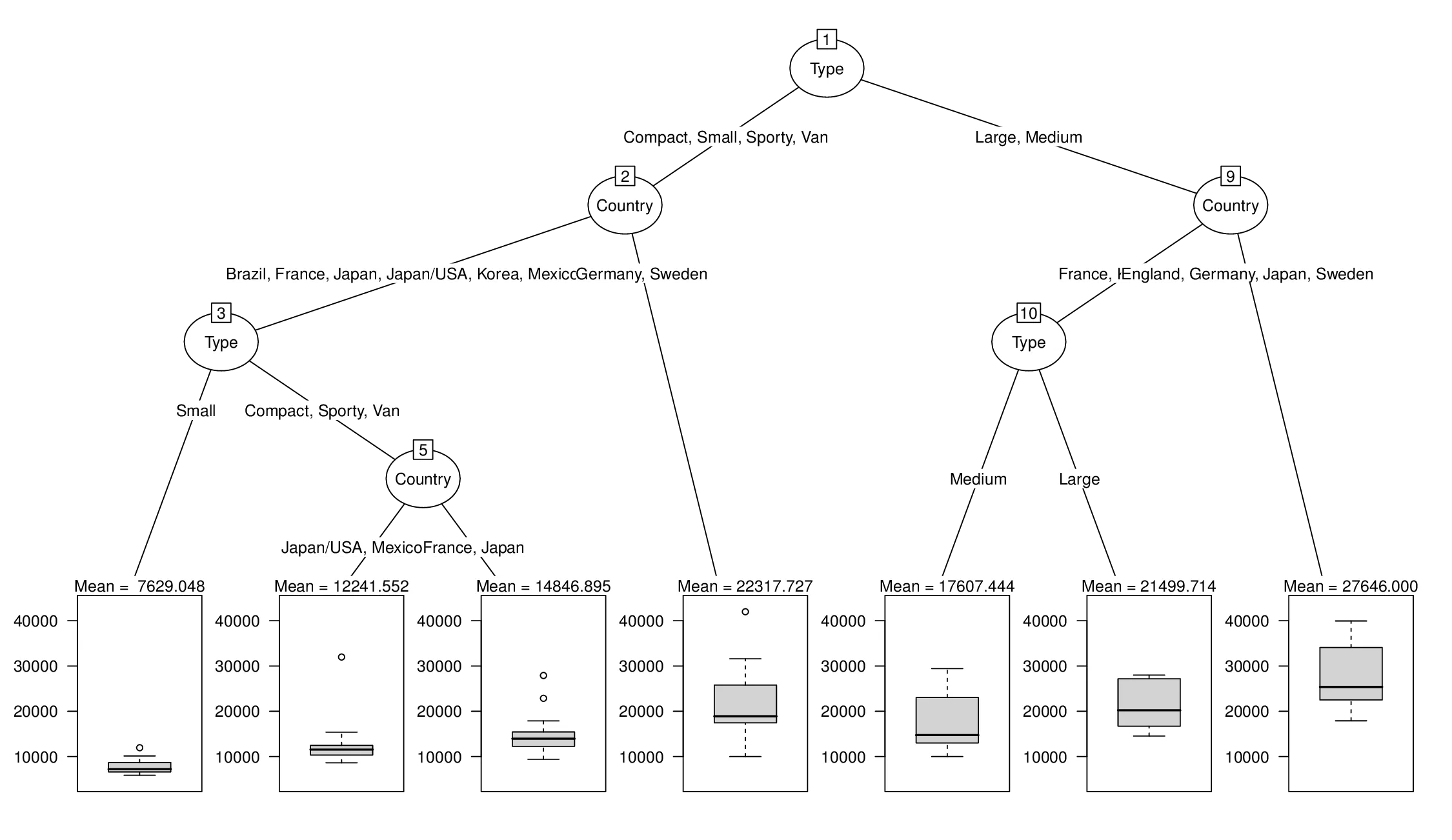
fit <- rpart(Price ~ Mileage + Type + Country, cu.summary)par(xpd = TRUE)plot(fit, compress = TRUE)text(fit, use.n = TRUE)tree.2<-as.party(fit)plot(tree.2)这将生成一个带有终端节点箱线图的树状图。我想要做的是在每个终端节点上方放置平均值(以及稍后的其他百分位数)标签。因此,左侧的终端节点的标签将显示为“mean = 7629.048”,而不是“Node 4(n=21)”。 - djr99