我正在尝试从澳大利亚证券交易所网站创建一个PDF提取器,它将允许我搜索公司发布的所有“公告”,并在这些公告的PDF中搜索关键词。
到目前为止,我使用了requests库。下面是我的代码:
然而打印出来的是以下字符串(由于太长,我将截断):
我在StackExchange和其他网站上搜索了几天,尝试使用
到目前为止,我使用了requests库。下面是我的代码:
import requests
url = 'http://www.asx.com.au/asxpdf/20171103/pdf/43nyyw9r820c6r.pdf'
response = requests.get(url)
print(response.content)
然而打印出来的是以下字符串(由于太长,我将截断):
> b'%PDF-1.5\r%\xe2\xe3\xcf\xd3\r\n5 0 obj\r<</E 212221/H [ 1081 145 ]/L
> 212973/Linearized 1/N 1/O 8/T 212553>>\rendobj\r
> \r\r42 0 obj\r<</DecodeParms <</Columns 5/Predictor 12>>/Encrypt 7 0
> R/Filter /FlateDecode/ID [(\\216\\203\\217T\\n\\f\\236\\345?%\\214t4
> E\\271) (\\216\\203\\217T\\n\\f\\236\\345?%\\214t4 E\\271)]/Index [5
> 38]/Info 3 0 R/Length 86/Prev 212554/Root 6 0 R/Size 43/Type /XRef/W
> [1 3
> 1]>>\rstream\nx\x9ccbd`\x10``b``:\x04"\x19\xab\xc1d-X\xc4\x06D2\xac\x02\xb3\x93\xc0\xe2\x1d
> \x92?\x07,\x1e\t"\xb9T\x80$\xe3\x84\xcb@\x92\xa9m"\x03\x13\xe3\xdf\x13Z`Y\x06\xc6\x01#\xff3\xb0h\xbcfb`\xb6\x12\x02\xba\xe4\xef!S\x06\x0
我在StackExchange和其他网站上搜索了几天,尝试使用
print(response.content.decode('utf-8')和ASCII编码,但都无法让我读懂内容。抱歉,我知道我是个新手,希望能得到帮助。非常感谢。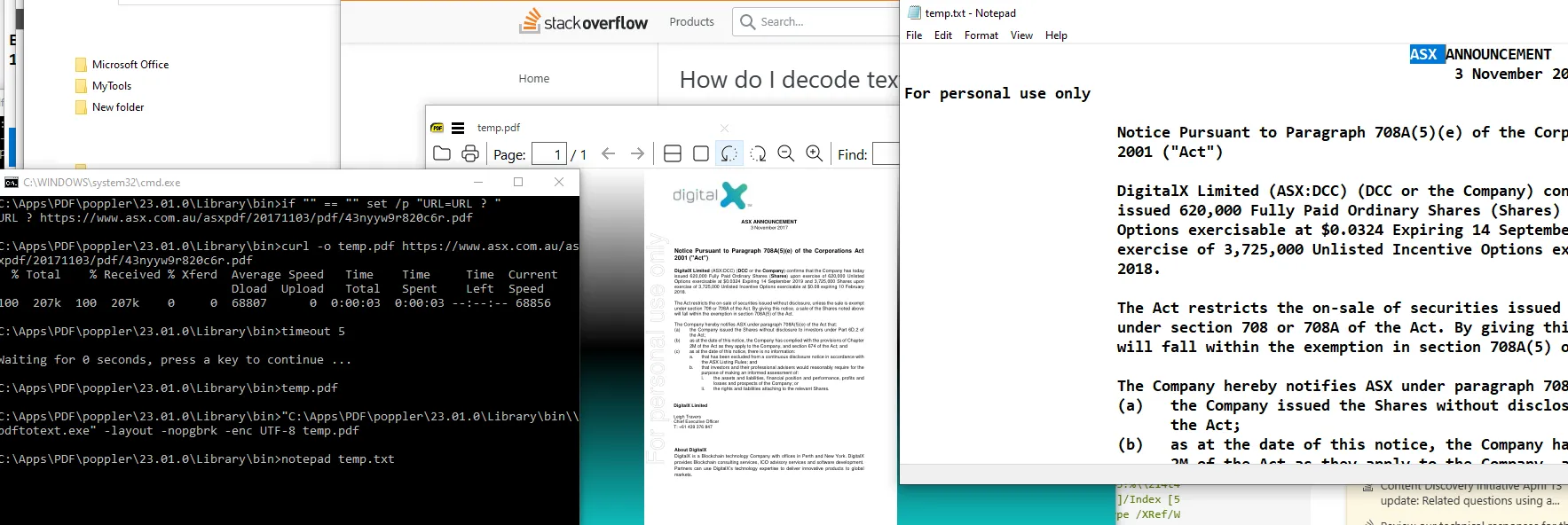
PyPDF2.PdfReader替换PyPDF2.PdfFileReader,并使用read_pdf.pages[0].extract_text()替换read_pdf.getPage(0).extractText()。 - Nicolas Dao