假设我有一个包含三列的数据框:日期、股票代码、数值(没有索引,至少最初没有)。我有许多日期和许多股票代码,但每个(ticker, date)元组是唯一的。(但显然相同的日期会出现在许多行中,因为它将存在于多个股票代码中,并且相同的股票代码将出现在多行中,因为它将存在于多个日期中。)
最初,我的行是特定顺序,但不是按任何列排序。
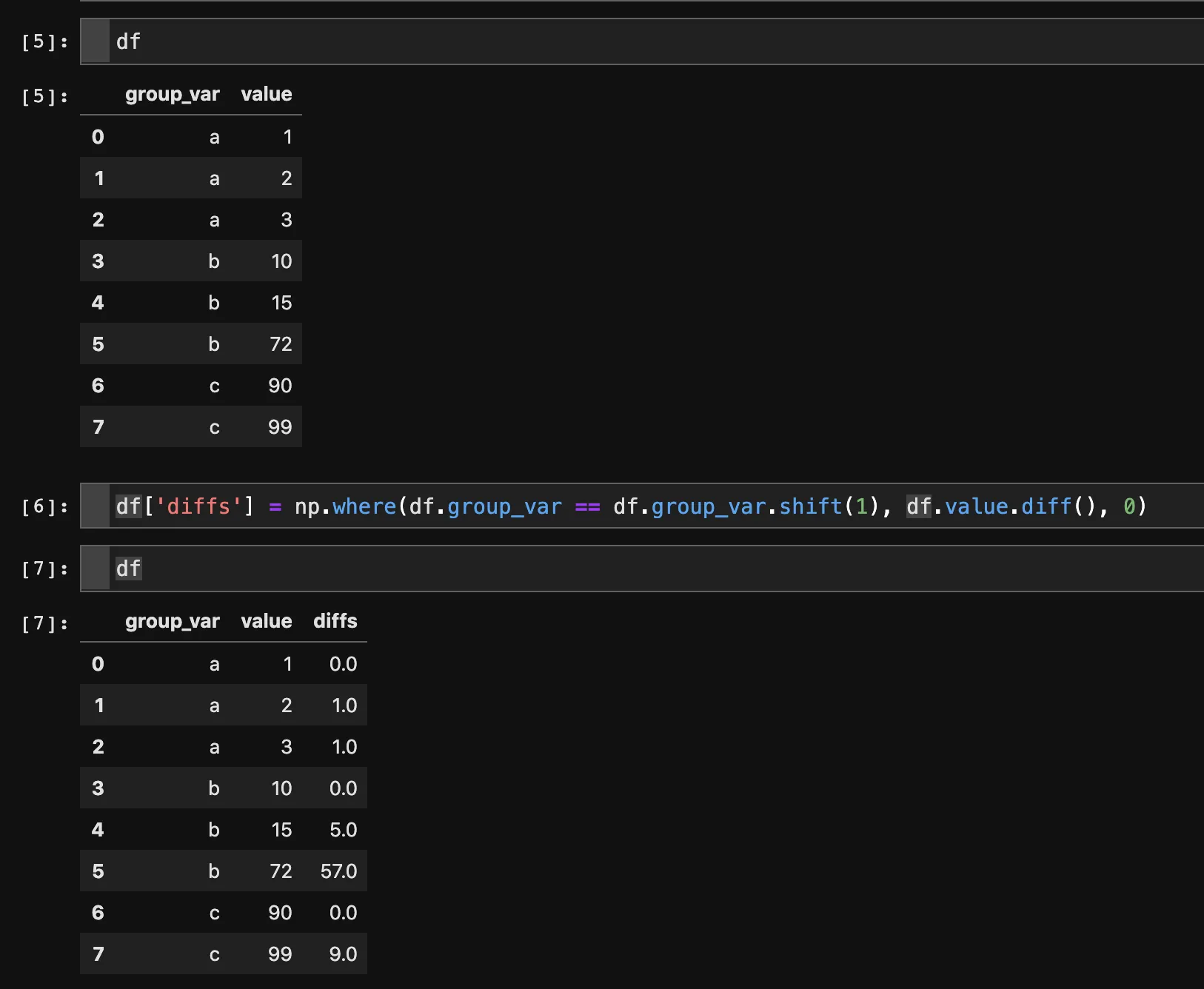
我想计算每个股票代码(按日期排序)的第一次差异(每日变化),并将其放入数据框的新列中。 在这种情况下,我不能简单地这样做。
这似乎是使用
1. 基于它们的代码将行分组 2. 在每个组内,按其日期对行进行排序 3. 在每个排序后的组内,计算
我必须想象这是一个单行程序。但我错过了什么吗?
最初,我的行是特定顺序,但不是按任何列排序。
我想计算每个股票代码(按日期排序)的第一次差异(每日变化),并将其放入数据框的新列中。 在这种情况下,我不能简单地这样做。
df['diffs'] = df['value'].diff()
因为相邻的行不来自同一支票券。像这样排序:
df = df.sort(['ticker', 'date'])
df['diffs'] = df['value'].diff()
NaN。这似乎是使用
groupby的明显时机,但出于某种原因,我似乎无法使其正常工作。明确地说,我想执行以下过程:1. 基于它们的代码将行分组 2. 在每个组内,按其日期对行进行排序 3. 在每个排序后的组内,计算
value列的差异
4. 将这些差异放入原始数据框中的新diffs列中(理想情况下保留原始数据框的顺序)。我必须想象这是一个单行程序。但我错过了什么吗?
在2013-12-17晚上9:00编辑
好...有进展了。我可以执行以下操作以获取新数据框:
result = df.set_index(['ticker', 'date'])\
.groupby(level='ticker')\
.transform(lambda x: x.sort_index().diff())\
.reset_index()
但如果我理解groupby的机制,那么我的行将首先按ticker排序,然后再按date排序。是这样吗?如果是的话,我需要执行合并操作将差异列(当前在result['current']中)追加到原始数据框df中吗?
(ticker, date)元组定义)很重要怎么办?你会在原始数据框的副本上使用你的解决方案,然后合并(以ticker和date为键)吗? - 8one6ticker前N个样本的平均值。 - 8one6df.pivot_table( cols='ticker', rows='date', values='value' ),@DJ_8one6。 - behzad.nouriset_index、groupby、transform、reset_index)与您提到的重新索引相结合,以在过程结束时进行“重新对齐”?我认为groupby结构在强制执行计算不“跨组”方面具有很大的价值。 - 8one6groupby,但可以轻松使用此方法来计算滚动平均值或类似内容。 - behzad.nouri