批量转换为PNG文件
https://github.com/myleott/mnist_png/blob/400fe88faba05ae79bbc2107071144e6f1ea2720/convert_mnist_to_png.py 包含一个很好的PNG提取示例,使用GPL 2.0许可证。使用像Pillow这样的库应该很容易适应其他输出格式。
他们还有一个预先提取的存档:https://github.com/myleott/mnist_png/blob/master/mnist_png.tar.gz?raw=true
用法:
wget \
http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz \
http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz \
http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz \
http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz
gunzip --keep *-ubyte.gz
python3 -m pip install pypng==0.20220715.0
./convert_mnist_to_png.py . out
现在out/包含了如下文件:
out/training/0/1.png

out/training/0/21.png

out/training/1/3.png

out/training/1/6.png
out/testing/0/10.png

out/testing/0/13.png

convert_mnist_to_png.py
import os
import struct
import sys
from array import array
from os import path
import png
def read(dataset = "training", path = "."):
if dataset is "training":
fname_img = os.path.join(path, 'train-images-idx3-ubyte')
fname_lbl = os.path.join(path, 'train-labels-idx1-ubyte')
elif dataset is "testing":
fname_img = os.path.join(path, 't10k-images-idx3-ubyte')
fname_lbl = os.path.join(path, 't10k-labels-idx1-ubyte')
else:
raise ValueError("dataset must be 'testing' or 'training'")
flbl = open(fname_lbl, 'rb')
magic_nr, size = struct.unpack(">II", flbl.read(8))
lbl = array("b", flbl.read())
flbl.close()
fimg = open(fname_img, 'rb')
magic_nr, size, rows, cols = struct.unpack(">IIII", fimg.read(16))
img = array("B", fimg.read())
fimg.close()
return lbl, img, size, rows, cols
def write_dataset(labels, data, size, rows, cols, output_dir):
output_dirs = [
path.join(output_dir, str(i))
for i in range(10)
]
for dir in output_dirs:
if not path.exists(dir):
os.makedirs(dir)
for (i, label) in enumerate(labels):
output_filename = path.join(output_dirs[label], str(i) + ".png")
print("writing " + output_filename)
with open(output_filename, "wb") as h:
w = png.Writer(cols, rows, greyscale=True)
data_i = [
data[ (i*rows*cols + j*cols) : (i*rows*cols + (j+1)*cols) ]
for j in range(rows)
]
w.write(h, data_i)
if __name__ == "__main__":
if len(sys.argv) != 3:
print("usage: {0} <input_path> <output_path>".format(sys.argv[0]))
sys.exit()
input_path = sys.argv[1]
output_path = sys.argv[2]
for dataset in ["training", "testing"]:
labels, data, size, rows, cols = read(dataset, input_path)
write_dataset(labels, data, size, rows, cols,
path.join(output_path, dataset))
使用以下方法检查生成的PNG文件:
identify out/testing/0/10.png
给出:
out/testing/0/10.png PNG 28x28 28x28+0+0 8-bit Gray 256c 272B 0.000u 0:00.000
因此它们看起来是灰度和8位,因此应该忠实地表示原始数据。
在Ubuntu 22.10上进行了测试。

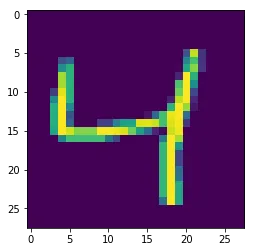

python-mnist软件包在PyPI上有一些代码可以完成这项工作。 - Kh40tiK.idx3-ubyte的文件格式在 THE MNIST DATABASE 页面中有详细描述。 - Laurent LAPORTE