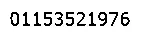我希望能从像这样的图像中提取文本(主要是数字)。

import pytesseract
from PIL import Image
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
img = Image.open('1.jpg')
text = pytesseract.image_to_string(img, lang='eng')
print(text)
但是我得到的只有这个(hE PPAR)