方法一(ID 值)
如果我们可以假设所有“合并”的组具有 ID 名称,这些名称是单个组的逗号分隔列表,则我们可以仅查看 ID 并忽略起始/结束信息来解决此问题。以下是一种这样的方法。
首先,通过查找带逗号的 ID 来查找所有“合并”的组。
groups<-Filter(function(x) length(x)>1,
setNames(strsplit(as.character(df$id),","),df$id))
现在,对于这些组中的每一个,确定哪个拥有更高的级别,是合并的组还是其中一个单独的组。然后将要删除的行的索引作为负数返回。
drops<-unlist(lapply(names(groups), function(g) {
mi<-which(df$id==g)
ii<-which(df$id %in% groups[[g]])
if(df[mi, "level"] > max(df[ii, "level"])) {
return(-ii)
} else {
return(-mi)
}
}))
最后,从数据框中删除它们。
df[drops,]
方法二(起始/结束图)
我想尝试一种忽略(非常有用的)合并ID名称,只考虑起始/结束位置的方法。可能我走了一条错误的路,但这让我想到了一个网络/图形问题,所以我使用了igraph库。
我创建了一个图形,其中每个顶点表示一个起始/结束位置。因此,每个边代表一个范围。我使用样本数据集中的所有范围,并填充任何缺失的范围,使图形连接。我将该数据合并在一起以创建一个边缘列表。对于每个边缘,我记住了原始数据集中的“级别”和“ID”值。以下是执行此操作的代码:
library(igraph)
poslist<-sort(unique(c(df$start, df$end)))
seq.el<-embed(rev(poslist),2)
class(seq.el)<-"character"
colnames(seq.el)<-c("start","end")
el<-rbind(df[,c("start","end","level", "id")],data.frame(seq.el, level=0, id=""))
el<-el[!duplicated(el[,1:2]),]
gg<-graph.data.frame(el)
这将创建一个类似于以下图片的图形:
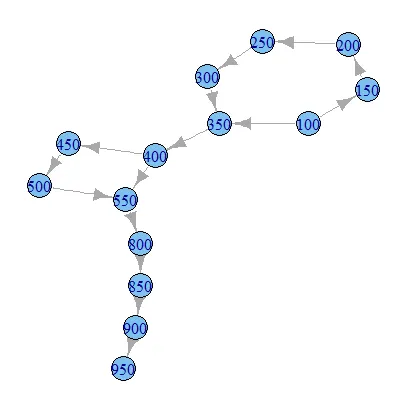
因此,我们希望通过选择具有最大“level”值的边的路径来消除图中的循环。不幸的是,由于这不是一种常规的路径加权方案,我没有找到使用默认算法轻松完成此操作的方法(也许我错过了)。所以我不得不编写自己的图遍历函数。虽然它不如我所希望的那样漂亮,但在这里它就是。
findPath <- function(gg, fromv, tov) {
if ((missing(tov) && length(incident(gg, fromv, "in"))>1) ||
(!missing(tov) && V(gg)[fromv]==V(gg)[tov])) {
return (list(level=0, path=numeric()))
}
es <- E(gg)[from(fromv)]
if (length(es)>1) {
pp <- lapply(get.edges(gg, es)[,2], function(v) {
edg <- E(gg)[fromv %--% v]
lvl <- edg$level
nxt <- findPaths(gg,v)
return (list(level=max(lvl, nxt$level), path=c(edg,nxt$path)))
})
lvl <- sapply(pp, `[[`, "level")
take <- pp[[which.max(lvl)]]
nxt <- findPaths(gg, get.edges(gg, tail(take$path,1))[,2], tov)
return (list(level=max(take$level, nxt$level), path=c(take$path, nxt$path)))
} else {
lvl <- E(gg)[es]$level
nv <- get.edges(gg,es)[,2]
nxt <- findPaths(gg, nv, tov)
return (list(level=max(lvl, nxt$level), path=c(es, nxt$path)))
}
}
这将会找到两个节点之间的一条路径,该路径满足在遇到分支时具有最大级别的属性。我们将这称为使用此数据集进行的操作。
rr <- findPaths(gg, "100","950")$path
这将找到最终路径。由于原始
df 数据框中的每一行都代表一条边,我们只需要从与最终路径相对应的路径中提取边。这实际上给出了一条路径,它看起来像
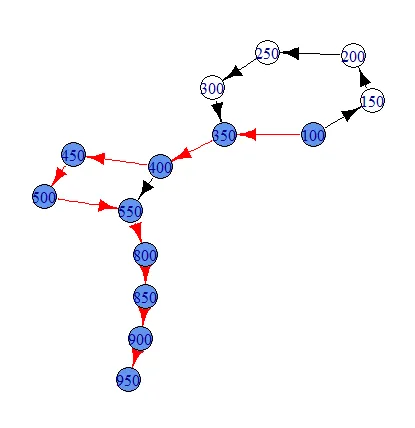
其中红色路径是所选路径。然后我可以使用子集
df
df[df$id %in% na.omit(E(gg)[rr]$id), ]
方法三(重叠矩阵)
这是另一种查看开始/停止位置的方式。我创建了一个矩阵,其中列对应于数据框行中的范围,矩阵的行对应于位置。如果范围与位置重叠,则矩阵中的每个值都为true。在这里,我使用between.R助手函数。
un<-sort(unique(unlist(df[,2:3])))
cc<-sapply(1:nrow(df), function(i) between(un, df$start[i], df$end[i]))
groups<-cumsum(c(F,rowSums(cc[-1,]& cc[-nrow(cc),])==0))
keeps<-lapply(split.data.frame(cc, groups), function(m) {
lengths <- colSums(m)
mx <- which.max(lengths)
gx <- setdiff(which(lengths>0), mx)
if(length(gx)>0) {
if(df$level[mx] > max(df$level[gx])) {
mx
} else {
gx
}
} else {
mx
}
})
这将给出每个组要保留的ID列表,我们可以使用它来获取最终的数据集。
df[unlist(keeps),]
方法四(开/关清单)
我有一个最后的方法。这可能是最具可扩展性的方法。我们基本上将职位融合在一起,并跟踪开放和关闭事件以识别组。然后我们拆分并查看每个组中最长的是否具有最大级别。最终,我们返回ID。该方法使用所有标准基本功能。
dd<-rbind(
cbind(df[,c(1,4)],pos=df[,2], evt=1),
cbind(df[,c(1,4)],pos=df[,3], evt=-1)
)
dd<-dd[order(dd$pos, -dd$evt),]
dd$open <- cumsum(dd$evt)
dd$group <- cumsum(c(0,head(dd$open,-1)==0))
dd$width <- ave(dd$pos, dd$id, FUN=function(x) diff(range(x)))
dd <- subset(dd, evt==1,select=c("id","level","width","group"))
ids<-unlist(lapply(split(dd, dd$group), function(x) {
if(nrow(x)==1) return(x$id)
mw<-which.max(x$width)
ml<-which.max(x$level)
if(mw==ml) {
return(x$id[mw])
} else {
return(x$id[-mw])
}
}))
最后进行子集操作。
df[df$id %in% ids, ]
到目前为止,我想你已经知道这返回什么了。
总结
因此,如果您的真实数据具有与示例数据相同类型的ID,则显然方法1是更好、更直接的选择。我仍然希望有一种简化方法2的方式,但我可能错过了什么。我没有进行任何关于这些方法的效率或性能测试。我猜想方法4可能是最有效的,因为它应该呈线性比例缩放。