我尝试了"heapq",但得出结论:我的期望与屏幕上看到的不同。我需要有人解释它是如何工作以及在哪些情况下可以有用。
从书籍《Python Module of the Week》第2.2节排序中写道:
如果你需要在添加或删除值时维护已排序的列表,请查看heapq。通过使用heapq中的函数向列表添加或删除项目,您可以以低开销地维护列表的排序顺序。
以下是我的操作和结果。
import heapq
heap = []
for i in range(10):
heap.append(i)
heap
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
heapq.heapify(heap)
heapq.heappush(heap, 10)
heap
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
heapq.heappop(heap)
0
heap
[1, 3, 2, 7, 4, 5, 6, 10, 8, 9] <<< Why the list does not remain sorted?
heapq.heappushpop(heap, 11)
1
heap
[2, 3, 5, 7, 4, 11, 6, 10, 8, 9] <<< Why is 11 put between 4 and 6?
所以,正如你所看到的,“堆”列表根本没有排序,实际上你添加和删除项目的次数越多,它就会变得越混乱。推入的值取不可解释的位置。
这是怎么回事?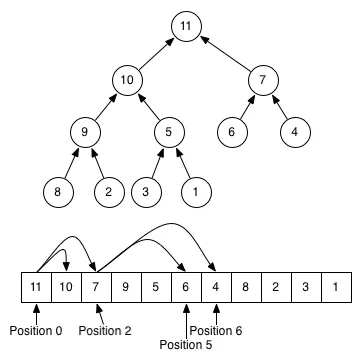
heapq的理论。 - jfsheapq维护一个排序列表。 - minerals