一种numpy解决方案:
import numpy as np
import pandas as pd
df = pd.DataFrame({
'col1': {0: [1, 'a'], 1: [2, 'b'], 2: [3, 'c']},
'col2': {0: [1, 'a1'], 1: [2, 'b1'], 2: [3, 'c1']},
'col3': {0: [1, 'a2'], 1: [2, 'b2'], 2: [3, 'c2']}
})
a = np.array(df.values.tolist())
new_df = pd.DataFrame(
np.concatenate((a[..., 1], a[:, 0, 0, None]), axis=1),
columns=[*df.columns, 'col4']
)
print(new_df)
new_df:
col1 col2 col3 col4
0 a a1 a2 1
1 b b1 b2 2
2 c c1 c2 3
通过perfplot提供一些时间信息:
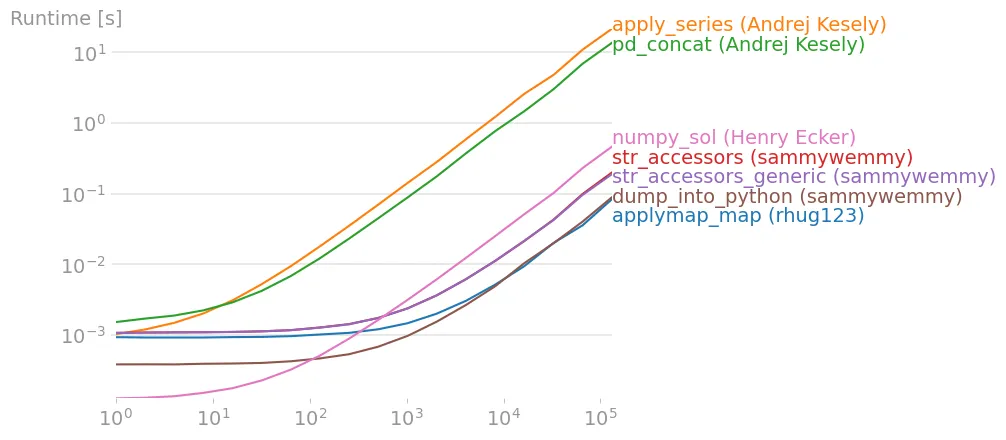
import numpy as np
import pandas as pd
import perfplot
def gen_data(n):
df = pd.DataFrame(
{'col1': [[1, 'a']],
'col2': [[1, 'a1']],
'col3': [[1, 'a2']]},
)
df = df.loc[np.repeat(df.index.values, n)]
return df
def applymap(df):
return df.applymap(lambda x: x[-1]).assign(
col4=df['col1'].map(lambda x: x[0]))
def apply_series(df):
return df.apply(lambda x: [v[1] for v in x] + [x[0][0]], axis=1) \
.apply(pd.Series) \
.rename(columns=lambda x: "col{}".format(x + 1))
def pd_concat(df):
return pd.concat(
[
df.transform(lambda x: [v[1] for v in x], axis=1),
df.apply(lambda x: x[0][0], axis=1).rename("col4"),
],
axis=1,
)
def str_accessors(df):
return df.assign(col1=df.col1.str[-1],
col2=df.col2.str[-1],
col3=df.col3.str[-1],
col4=df.col1.str[0])
def str_accessors_generic(df):
result = {col: df[col].str[-1] for col in df}
col4 = df.col1.str[0]
return df.assign(**result, col4=col4)
def dump_into_python(df):
outcome = {key: [ent[-1] for ent in value]
for key, value in df.items()}
col4 = {'col4': [value[-0] for value in df.col1]}
outcome = outcome | col4
return pd.DataFrame(outcome)
def numpy_sol(df):
a = np.array(df.values.tolist())
return pd.DataFrame(
np.concatenate((a[..., 1], a[:, 0, 0, None]), axis=1),
columns=[*df.columns, 'col4']
)
if __name__ == '__main__':
out = perfplot.bench(
setup=gen_data,
kernels=[
applymap,
apply_series,
pd_concat,
str_accessors,
str_accessors_generic,
dump_into_python,
numpy_sol
],
labels=[
'applymap_map (rhug123)',
'apply_series (Andrej Kesely)',
'pd_concat (Andrej Kesely)',
'str_accessors (sammywemmy)',
'str_accessors_generic (sammywemmy)',
'dump_into_python (sammywemmy)',
'numpy_sol (Henry Ecker)',
],
n_range=[2 ** k for k in range(18)],
equality_check=None
)
out.save('perfplot_results.png', transparent=False)
col1中的第一个值是1,而col2中的第一个值是2(在同一行中),那该怎么办? - Andrej Kesely