简短故事
根据我对几种不同的 Oracle 和 OpenJDK 实现进行的测试,似乎 Arrays.equals(char[], char[]) 比其他类型的所有变体都快约 8 倍。
如果您的应用程序性能与比较数组的相等性密切相关0,那么这意味着您几乎希望将所有数据强制转换为char[],以获得此神奇性能提升。
长故事
最近我在编写一些高性能代码,使用Arrays.equals(...)来比较用于索引结构的键。这些键可能非常长,并且通常仅在后面的字节中有所不同,因此此方法的性能非常重要。
有一段时间我使用的键的类型是char[],但是随着将服务泛化并避免来自底层byte[]和ByteBuffer的一些拷贝,我将其更改为byte[]。突然间2,许多基本操作的性能下降了约 3 倍。我追溯到上述事实:Arrays.equals(char[], char[])似乎比所有其他Arrays.equals()版本都享有特殊地位,包括取short[]的那个版本,这在语义上是相同的(并且可以使用相同的底层代码实现,因为符号对等式的行为没有影响)。
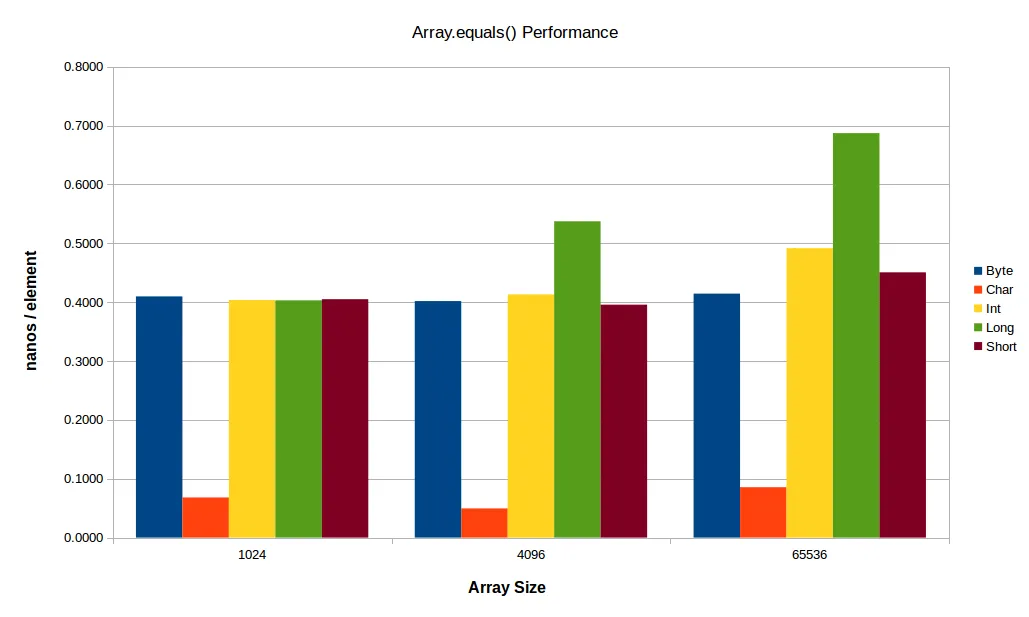
因此,我编写了一个JMH基准测试来测试所有的Arrays.equals(...)1原始变量及其char[]的变体表现最优,如上图所示。
现在,这种8倍的优势并没有在较小或较大的数组中同样地延伸到相同的数量级 - 但它仍然更快。
对于小数组来说,似乎常数开始占主导地位,而对于大数组来说,L2 / L3或主内存带宽开始发挥作用(您已经可以在早期的图表中相当清楚地看到后一种效应,在大尺寸时int[]和特别是long[]数组的性能开始下降)。下面是同样的测试结果,但使用了一个较小的小数组和一个较大的大数组:
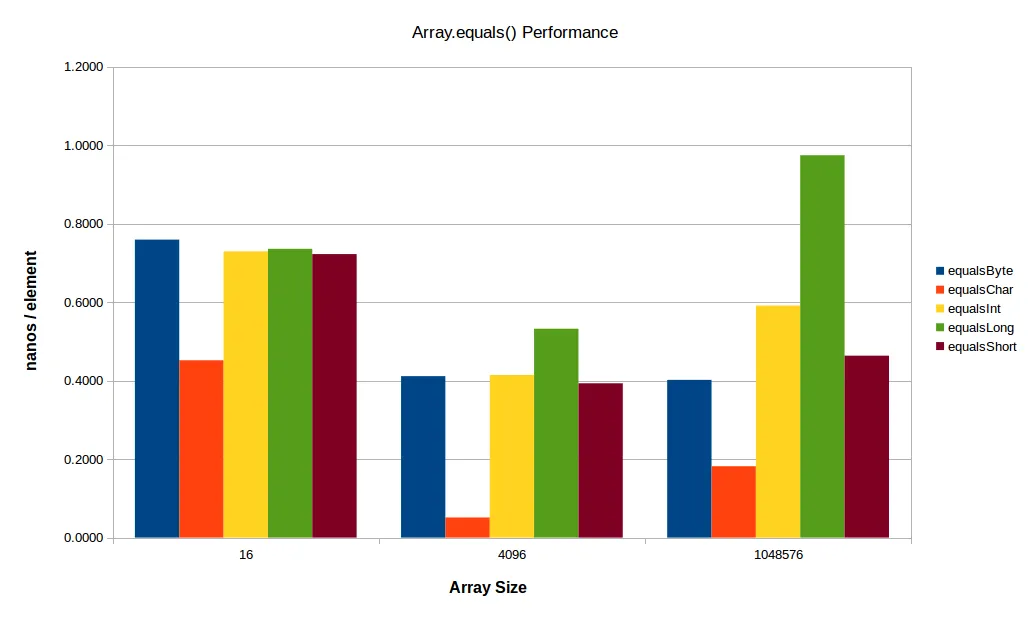
在此图表中,char[]仍然表现优异,只是不像以前那么明显。小数组的每个元素时间是标准时间的两倍左右(仅有16个元素),这可能是由于函数开销造成的:在每个元素约0.5纳秒的速度下,char[]变体仍然只需要大约7.2纳秒的时间完成整个调用,或者在我的机器上约为19个周期 - 因此少量的方法开销会严重影响运行时间(而基准测试本身的开销也需要几个周期)。
在较大的尺寸上,缓存和/或内存带宽是一个主要因素 - long[]变体需要的时间几乎是int[]变体的两倍。而short[]和特别是byte[]变体并不是很有效(它们的工作集仍适合我机器上的L3)。
char[]和其他所有类型之间的区别是极端的,在那些依赖于数组比较的应用程序中(对于某些特定领域实际上并不那么不寻常),值得尝试将您所有的数据放入char[]以利用它。这是为什么?char是否因为是String方法的基础而获得特殊处理?还是JVM优化了在基准测试中频繁使用的方法,而没有将同样(显而易见的)优化扩展到其他原始类型(特别是此处相同的short)?
0 ... 这甚至都不算太疯狂——考虑一下各种系统,例如依赖于(冗长的)哈希比较来检查值是否相等的系统,或键为长整型或可变大小的哈希映射。 1 我没有包括
boolean[]、float[]和double[]或双精度浮点数在结果中,以避免使图表杂乱无章,但要记录下来boolean[]和float[]与int[]的性能相同,而double[]与long[]的性能相同。这符合类型的底层大小。
2 我在这里撒了一个小谎。性能可能突然改变,但直到我运行了一系列其他更改后再次运行基准测试时才注意到,导致我确定了因果关系的痛苦二分过程。这是拥有某种类型的性能测量持续集成的一个很好的理由。
short[]没有得到相同的处理方式,因为对于这个操作它是相同的,这使得问题变得更加复杂)。 - BeeOnRope