假设有这样一个数据框:
当然,我可以循环遍历数据并创建一个新的列表,但肯定有更好的方法。你有什么想法吗?
df = pd.DataFrame([[1,2,3,4],[5,6,7,8],[9,10,11,12]], columns = ['A', 'B', 'A1', 'B1'])
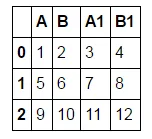
我希望有一个看起来像这样的数据框:
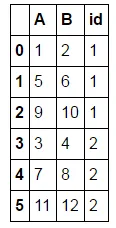
new_rows = int(df.shape[1]/2) * df.shape[0]
new_cols = 2
df.values.reshape(new_rows, new_cols, order='F')
当然,我可以循环遍历数据并创建一个新的列表,但肯定有更好的方法。你有什么想法吗?