如何传递类对象,特别是STL对象到C++ DLL并从DLL返回?
我的应用程序必须与以DLL文件形式存在的第三方插件交互,我无法控制这些插件使用的编译器。我知道STL对象没有保证的ABI,并且我担心会导致我的应用程序不稳定。
extern "C"创建一个普通的C接口,因为C ABI是明确定义且稳定的。
int 可能会对齐到 4 字节的边界。#pragma pack预处理器指令来解决此问题,这将强制编译器应用特定的对齐方式。如果您选择的对齐值比编译器选择的要大,则编译器仍将应用默认的对齐方式,因此,如果您选择了较大的对齐值,则类在不同编译器之间仍可能存在不同的对齐方式。解决此问题的方法是使用#pragma pack(1),这将强制编译器将数据成员对齐到一个字节边界上(基本上不会应用任何对齐方式)。这不是一个好主意,因为它可能会导致性能问题甚至在某些系统上崩溃。 但是,它确保了类的数据成员在内存中对齐的一致性。
成员重新排序
如果你的类不是标准布局, 编译器可以重新排列其数据成员在内存中。没有关于如何做到这一点的标准,因此任何数据重排都可能导致编译器之间不兼容。因此,来回传递数据到DLL将需要标准布局类。 调用约定 给定函数可以有多个调用约定。这些调用约定指定如何将数据传递给函数:参数存储在寄存器还是堆栈中?参数以何种顺序推送到堆栈上?谁清理函数完成后堆栈上剩余的任何参数?_cdecl,并尝试使用 _stdcall 进行调用,那么 会发生糟糕的事情。然而,_cdecl 是 C++ 函数的默认调用约定,所以除非你在一个地方指定了 _stdcall,在另一个地方指定了 _cdecl,否则这一点不会出现问题。
数据类型大小
根据此文档,在Windows上,大多数基本数据类型的大小都相同,无论您的应用程序是32位还是64位。但是,由于给定数据类型的大小是由编译器而不是任何标准强制执行的(所有标准都保证 1 == sizeof(char) <= sizeof(short) <= sizeof(int) <= sizeof(long) <= sizeof(long long)),因此最好使用固定大小的数据类型尽可能确保数据类型大小的兼容性。
堆问题
如果您的DLL链接到与EXE不同版本的C运行时,则两个模块将使用不同的堆。这是一个非常可能的问题,因为这些模块是使用不同的编译器编译的。malloc/free,因为它们不能保证按照你期望的方式工作。
STL 问题
C++标准库存在自己的ABI问题。不能保证给定的STL类型在内存中的布局方式相同,也不能保证给定的STL类在不同的实现中具有相同的大小(特别是调试构建可能会将额外的调试信息放入给定的STL类型中)。因此,在通过DLL边界传递之前,任何STL容器都必须被解包为基本类型,并在另一侧重新打包。GetProcAddress,则调用将失败,您将无法使用DLL。这需要一些技巧来解决,这也是跨DLL边界传递C++类的一个相当重要的原因。GetCCDLL函数。在我的系统上,以下.def文件适用于GCC和MSVC:EXPORTS
GetCCDLL=_Z8GetCCDLLv @1
MSVC:
EXPORTS
GetCCDLL=?GetCCDLL@@YAPAUCCDLL_v1@@XZ @1
结合所有这些解决方法并在模板和运算符的一些创意工作的基础上构建,我们可以尝试安全地通过DLL边界传递对象。请注意,C++11支持是必需的,以及对#pragma pack及其变体的支持; MSVC 2013提供此支持,最近版本的GCC和clang也是如此。
//POD_base.h: defines a template base class that wraps and unwraps data types for safe passing across compiler boundaries
//define malloc/free replacements to make use of Windows heap APIs
namespace pod_helpers
{
void* pod_malloc(size_t size)
{
HANDLE heapHandle = GetProcessHeap();
HANDLE storageHandle = nullptr;
if (heapHandle == nullptr)
{
return nullptr;
}
storageHandle = HeapAlloc(heapHandle, 0, size);
return storageHandle;
}
void pod_free(void* ptr)
{
HANDLE heapHandle = GetProcessHeap();
if (heapHandle == nullptr)
{
return;
}
if (ptr == nullptr)
{
return;
}
HeapFree(heapHandle, 0, ptr);
}
}
//define a template base class. We'll specialize this class for each datatype we want to pass across compiler boundaries.
#pragma pack(push, 1)
// All members are protected, because the class *must* be specialized
// for each type
template<typename T>
class pod
{
protected:
pod();
pod(const T& value);
pod(const pod& copy);
~pod();
pod<T>& operator=(pod<T> value);
operator T() const;
T get() const;
void swap(pod<T>& first, pod<T>& second);
};
#pragma pack(pop)
//POD_basic_types.h: holds pod specializations for basic datatypes.
#pragma pack(push, 1)
template<>
class pod<unsigned int>
{
//these are a couple of convenience typedefs that make the class easier to specialize and understand, since the behind-the-scenes logic is almost entirely the same except for the underlying datatypes in each specialization.
typedef int original_type;
typedef std::int32_t safe_type;
public:
pod() : data(nullptr) {}
pod(const original_type& value)
{
set_from(value);
}
pod(const pod<original_type>& copyVal)
{
original_type copyData = copyVal.get();
set_from(copyData);
}
~pod()
{
release();
}
pod<original_type>& operator=(pod<original_type> value)
{
swap(*this, value);
return *this;
}
operator original_type() const
{
return get();
}
protected:
safe_type* data;
original_type get() const
{
original_type result;
result = static_cast<original_type>(*data);
return result;
}
void set_from(const original_type& value)
{
data = reinterpret_cast<safe_type*>(pod_helpers::pod_malloc(sizeof(safe_type))); //note the pod_malloc call here - we want our memory buffer to go in the process heap, not the possibly-isolated DLL heap.
if (data == nullptr)
{
return;
}
new(data) safe_type (value);
}
void release()
{
if (data)
{
pod_helpers::pod_free(data); //pod_free to go with the pod_malloc.
data = nullptr;
}
}
void swap(pod<original_type>& first, pod<original_type>& second)
{
using std::swap;
swap(first.data, second.data);
}
};
#pragma pack(pop)
pod 类针对每种基本数据类型进行了专门的优化,因此 int 将自动包装为 int32_t,uint 将被包装为 uint32_t 等。这一切都是在幕后发生的,感谢重载的 = 和 () 运算符。我省略了其余的基本类型特化,因为它们几乎完全相同,除了底层数据类型(bool 特化有一点额外的逻辑,因为它被转换为一个 int8_t,然后将 int8_t 与 0 进行比较以转换回 bool,但这相当琐碎)。#pragma pack(push, 1)
template<typename charT>
class pod<std::basic_string<charT>> //double template ftw. We're specializing pod for std::basic_string, but we're making this specialization able to be specialized for different types; this way we can support all the basic_string types without needing to create four specializations of pod.
{
//more comfort typedefs
typedef std::basic_string<charT> original_type;
typedef charT safe_type;
public:
pod() : data(nullptr) {}
pod(const original_type& value)
{
set_from(value);
}
pod(const charT* charValue)
{
original_type temp(charValue);
set_from(temp);
}
pod(const pod<original_type>& copyVal)
{
original_type copyData = copyVal.get();
set_from(copyData);
}
~pod()
{
release();
}
pod<original_type>& operator=(pod<original_type> value)
{
swap(*this, value);
return *this;
}
operator original_type() const
{
return get();
}
protected:
//this is almost the same as a basic type specialization, but we have to keep track of the number of elements being stored within the basic_string as well as the elements themselves.
safe_type* data;
typename original_type::size_type dataSize;
original_type get() const
{
original_type result;
result.reserve(dataSize);
std::copy(data, data + dataSize, std::back_inserter(result));
return result;
}
void set_from(const original_type& value)
{
dataSize = value.size();
data = reinterpret_cast<safe_type*>(pod_helpers::pod_malloc(sizeof(safe_type) * dataSize));
if (data == nullptr)
{
return;
}
//figure out where the data to copy starts and stops, then loop through the basic_string and copy each element to our buffer.
safe_type* dataIterPtr = data;
safe_type* dataEndPtr = data + dataSize;
typename original_type::const_iterator iter = value.begin();
for (; dataIterPtr != dataEndPtr;)
{
new(dataIterPtr++) safe_type(*iter++);
}
}
void release()
{
if (data)
{
pod_helpers::pod_free(data);
data = nullptr;
dataSize = 0;
}
}
void swap(pod<original_type>& first, pod<original_type>& second)
{
using std::swap;
swap(first.data, second.data);
swap(first.dataSize, second.dataSize);
}
};
#pragma pack(pop)
//CCDLL.h: defines a DLL interface for a pod-based DLL
struct CCDLL_v1
{
virtual void ShowMessage(const pod<std::wstring>* message) = 0;
};
CCDLL_v1* GetCCDLL();
这只是创建了一个基本的接口,DLL和任何调用者都可以使用。请注意,我们传递的是指向pod的指针,而不是pod本身。现在我们需要在DLL端实现它:
struct CCDLL_v1_implementation: CCDLL_v1
{
virtual void ShowMessage(const pod<std::wstring>* message) override;
};
CCDLL_v1* GetCCDLL()
{
static CCDLL_v1_implementation* CCDLL = nullptr;
if (!CCDLL)
{
CCDLL = new CCDLL_v1_implementation;
}
return CCDLL;
}
现在让我们实现ShowMessage函数:
#include "CCDLL_implementation.h"
void CCDLL_v1_implementation::ShowMessage(const pod<std::wstring>* message)
{
std::wstring workingMessage = *message;
MessageBox(NULL, workingMessage.c_str(), TEXT("This is a cross-compiler message"), MB_OK);
}
没什么太花哨的东西:这只是将传递的pod复制到普通的wstring中,并在消息框中显示它。毕竟,这只是一个POC,而不是一个完整的实用程序库。
现在我们可以构建DLL。不要忘记特殊的.def文件以解决链接器的名称重整问题。(注意:我实际构建和运行的CCDLL结构比我在此处展示的更多函数。.def文件可能无法按预期工作。)
现在是调用DLL的EXE:
//main.cpp
#include "../CCDLL/CCDLL.h"
typedef CCDLL_v1*(__cdecl* fnGetCCDLL)();
static fnGetCCDLL Ptr_GetCCDLL = NULL;
int main()
{
HMODULE ccdll = LoadLibrary(TEXT("D:\\Programming\\C++\\CCDLL\\Debug_VS\\CCDLL.dll")); //I built the DLL with Visual Studio and the EXE with GCC. Your paths may vary.
Ptr_GetCCDLL = (fnGetCCDLL)GetProcAddress(ccdll, (LPCSTR)"GetCCDLL");
CCDLL_v1* CCDLL_lib;
CCDLL_lib = Ptr_GetCCDLL(); //This calls the DLL's GetCCDLL method, which is an alias to the mangled function. By dynamically loading the DLL like this, we're completely bypassing the name mangling, exactly as expected.
pod<std::wstring> message = TEXT("Hello world!");
CCDLL_lib->ShowMessage(&message);
FreeLibrary(ccdll); //unload the library when we're done with it
return 0;
}
这里是结果。我们的 DLL 起作用了。我们成功地解决了 STL ABI 问题、C++ ABI 问题和名称重载问题,我们的 MSVC DLL 可以与 GCC EXE 一起使用。
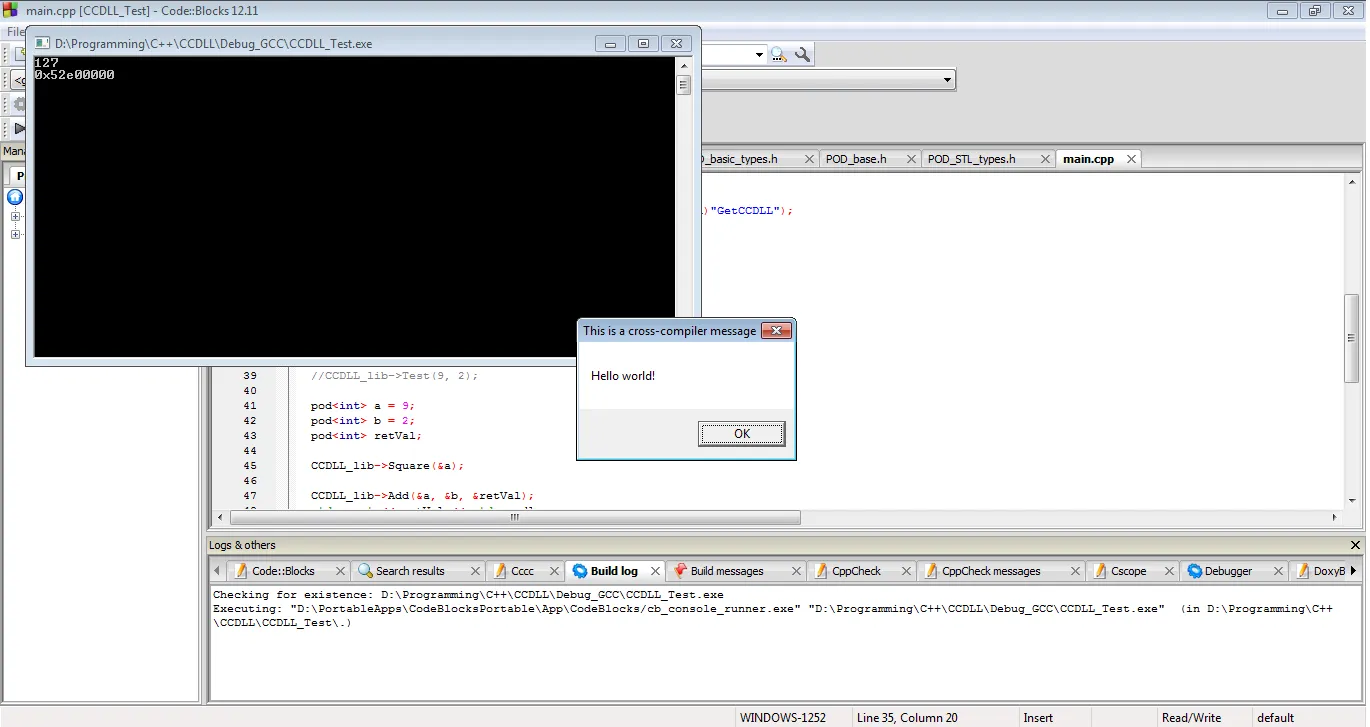
所以故事的寓意是...除了极少数例外情况,你需要一位负责接口的人,他可以确保与原始类型保持干净的ABI边界,避免过载。如果您可以接受这个条件,那么共享DLLs/SOs中类的接口就没必要害怕跨编译器。直接共享类==麻烦,但共享纯虚拟接口并不会那么糟糕。
除非所有模块(.EXE和.DLL)都使用相同的C++编译器版本、相同的CRT设置和风格,否则不能安全地在DLL边界传递STL对象,这是高度限制性的,显然不适用于您的情况。
如果您想从DLL中公开面向对象的接口,则应公开C++纯接口(类似于COM所做的)。考虑阅读CodeProject上这篇有趣的文章:
您还可以考虑在DLL边界处公开纯C接口,然后在调用站点构建C++包装器。
这类似于在Win32中发生的情况:Win32实现代码几乎是C++,但许多Win32 API公开了纯C接口(也有公开COM接口的API)。然后ATL/WTL和MFC使用C++类和对象包装这些纯C接口。