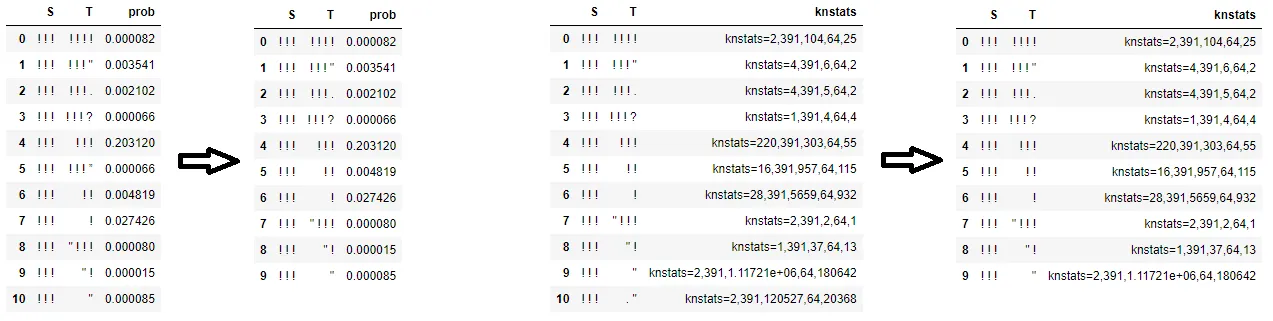
假设我有两个DataFrame,如下所示:
>>dfA
S T prob
0 ! ! ! ! ! ! 8.1623999e-05
1 ! ! ! ! ! ! " 0.00354090007
2 ! ! ! ! ! ! . 0.00210241997
3 ! ! ! ! ! ! ? 6.55684998e-05
4 ! ! ! ! ! ! 0.203119993
5 ! ! ! ! ! ! ” 6.62070015e-05
6 ! ! ! ! ! 0.00481862016
7 ! ! ! ! 0.0274260994
8 ! ! ! " ! ! ! 7.99940026e-05
9 ! ! ! " ! 1.51188997e-05
10 ! ! ! " 8.50678989e-05
>>dfB
S T knstats
0 ! ! ! ! ! ! ! knstats=2,391,104,64,25
1 ! ! ! ! ! ! " knstats=4,391,6,64,2
2 ! ! ! ! ! ! . knstats=4,391,5,64,2
3 ! ! ! ! ! ! ? knstats=1,391,4,64,4
4 ! ! ! ! ! ! knstats=220,391,303,64,55
5 ! ! ! ! ! knstats=16,391,957,64,115
6 ! ! ! ! knstats=28,391,5659,64,932
7 ! ! ! " ! ! ! knstats=2,391,2,64,1
8 ! ! ! " ! knstats=1,391,37,64,13
9 ! ! ! " knstats=2,391,1.11721e+06,64,180642
10 ! ! . " knstats=2,391,120527,64,20368
我想创建一个新的DataFrame,它由两个矩阵中具有匹配的"S"和"T"条目的行组成,同时还包括来自dfA的prob列和来自dfB的knstats列。结果应该看起来像下面这样,并且顺序相同很重要:
S T prob knstats
0 ! ! ! ! ! ! ! 8.1623999e-05 knstats=2,391,104,64,25
1 ! ! ! ! ! ! " 0.00354090007 knstats=4,391,6,64,2
2 ! ! ! ! ! ! . 0.00210241997 knstats=4,391,5,64,2
3 ! ! ! ! ! ! ? 6.55684998e-05 knstats=1,391,4,64,4
4 ! ! ! ! ! ! 0.203119993 knstats=220,391,303,64,55
5 ! ! ! ! ! 0.00481862016 knstats=16,391,957,64,115
6 ! ! ! ! 0.0274260994 knstats=28,391,5659,64,932
7 ! ! ! " ! ! ! 7.99940026e-05 knstats=2,391,2,64,1
8 ! ! ! " ! 1.51188997e-05 knstats=1,391,37,64,13
9 ! ! ! " 8.50678989e-05 knstats=2,391,1.11721e+06,64,180642