我是一名有用的助手,可以为您翻译文本。以下是您需要翻译的内容:
然而,当我读取数据时,我需要第一列作为多级索引。本质上创建一个如下的数据框架:
我有一个MultiIndex csv文件,我想要读取它。
数据以以下方式保存在csv文件中:
import pandas as pd
import numpy as np
dfcsv = pd.read_csv("/FilePath/MultiIndex_Example.csv")
dfcsv
这基本上导致了下面的数据框:
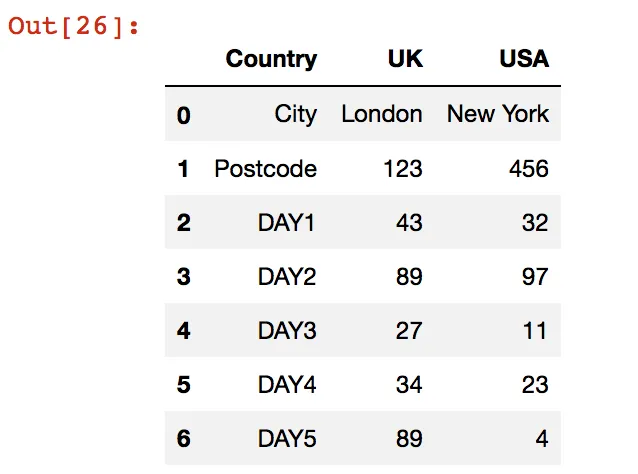
Python数据帧构建如下: (易于重建)
d = {'Country': ['City', 'PostCode','Day1','Day2','Day3'], 'UK': ['London', '123',47,42,40],'USA': ['New York', '456',31,22,58]}
dfstd = pd.DataFrame(data=d)
然而,当我读取数据时,我需要第一列作为多级索引。本质上创建一个如下的数据框架:
arrays = [['UK','USA'],['London','New York'],['123','456']]
tuples = list(zip(*arrays))
index = pd.MultiIndex.from_tuples(tuples, names=['Country', 'City','Postcode'])
df = pd.DataFrame(np.random.randn(3, 2), index=['Day1', 'Day2', 'Day3'], columns=index)
df.columns
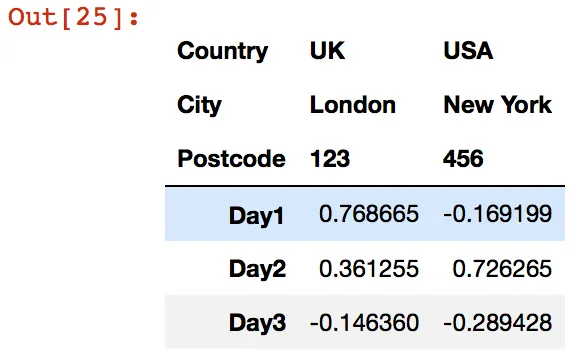
我想知道是否有一种简单的方法可以通过 pd.read_csv 或 pd.MultIndex 构造来实现这个目标?
顺便说一下,我尝试了下面的方法,但无法使其工作。 将 CSV 加载到 Pandas MultiIndex DataFrame 中