我有一个包含四列的csv文件。我可以这样读取它:
df = pd.read_csv('my.csv', error_bad_lines=False, sep='\t', header=None, names=['A', 'B', 'C', 'D'])
现在,字段C包含字符串值。但有些行中存在非字符串类型(浮点数或数字)的值。如何删除这些行?我正在使用Pandas的0.18.1版本。
我有一个包含四列的csv文件。我可以这样读取它:
df = pd.read_csv('my.csv', error_bad_lines=False, sep='\t', header=None, names=['A', 'B', 'C', 'D'])
现在,字段C包含字符串值。但有些行中存在非字符串类型(浮点数或数字)的值。如何删除这些行?我正在使用Pandas的0.18.1版本。
df = pd.DataFrame([['a', 'b', 'c', 'd'], ['e', 'f', 1.2, 'g']], columns=list('ABCD'))
print df
A B C D
0 a b c d
1 e f 1.2 g
请注意,您可以看到各个单元格类型是什么。
print type(df.loc[0, 'C']), type(df.loc[1, 'C'])
<type 'str'> <type 'float'>
掩码和切片
print df.loc[df.C.apply(type) != float]
A B C D
0 a b c d
print df.loc[df.C.apply(lambda x: not isinstance(x, (float, int)))]
A B C D
0 a b c d
你也可以使用float来尝试确定它是否为浮点数。
def try_float(x):
try:
float(x)
return True
except:
return False
print df.loc[~df.C.apply(try_float)]
A B C D
0 a b c d
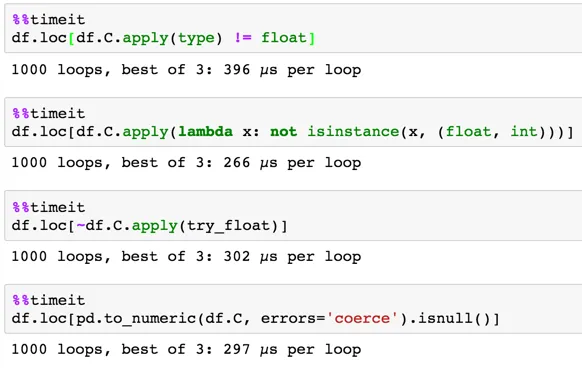
对于一个有500,000行的数据框:
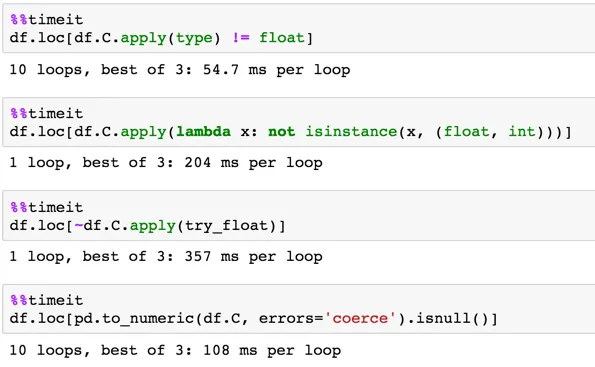
检查其类型是否为浮点数似乎是最高效的,紧随其后的是检查是否为数字。如果您需要检查整数和浮点数,则可以使用jezrael的答案。如果您可以使用检查浮点数来解决问题,则使用该方法。
to_numeric创建的mask和参数errors='coerce'一起使用布尔索引 - 在字符串值处得到NaN。然后检查isnull:df = pd.DataFrame({'A':[1,2,3],
'B':[4,5,6],
'C':['a',8,9],
'D':[1,3,5]})
print (df)
A B C D
0 1 4 a 1
1 2 5 8 3
2 3 6 9 5
print (pd.to_numeric(df.C, errors='coerce'))
0 NaN
1 8.0
2 9.0
Name: C, dtype: float64
print (pd.to_numeric(df.C, errors='coerce').isnull())
0 True
1 False
2 False
Name: C, dtype: bool
print (df[pd.to_numeric(df.C, errors='coerce').isnull()])
A B C D
0 1 4 a 1
使用 pandas.DataFrame.select_dtypes 方法。 例如。
df.select_dtypes(exclude='object')
or
df.select_dtypes(include=['int64','float','int'])
df.loc[df.C.apply(lambda x: isinstance(x, str))]- Aaron Bramson