我有一个 PySpark 数据框,看起来像这样:
我想要能够计算“我的列表(My_list)”列中的元素数量,并按降序排序。例如:
data2 = [("James",["A x","B z","C q","D", "E"]),
("Michael",["A x","C","E","K", "D"]),
("Robert",["A y","R","B z","B","D"]),
("Maria",["X","A y","B z","F","B"]),
("Jen",["A","B","C q","F","R"])
]
df2 = spark.createDataFrame(data2, ["Name", "My_list" ])
df2
Name My_list
0 James [A x, B z, C q, D, E]
1 Michael [A x, C, E, K, D]
2 Robert [A y, R, B z, B, D]
3 Maria [X, A y, B z, F, B]
4 Jen [A, B, C q, F, R]
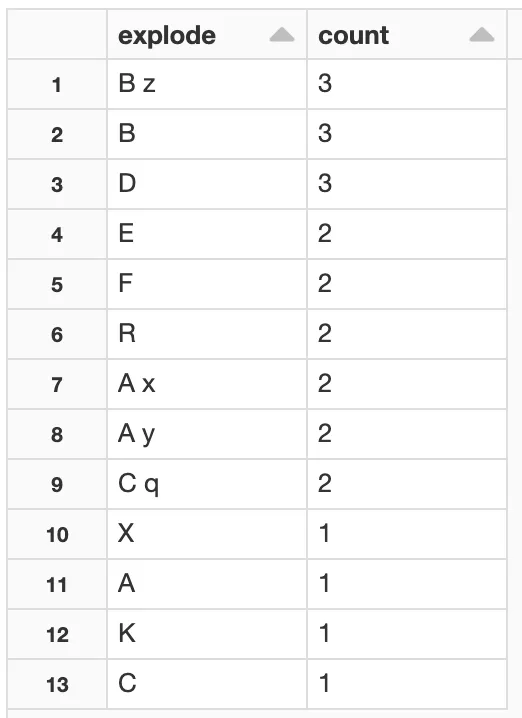
我想要能够计算“我的列表(My_list)”列中的元素数量,并按降序排序。例如:
'A x' appeared -> P times,
'B z' appeared -> Q times, and so on.
有人能解释一下这个吗?非常感谢您的帮助。