我习惯使用Python中的字典来表示图形,但是在处理大型图形和复杂计算时遇到了一些严重的性能问题,因此我认为我应该转而使用邻接矩阵来避免哈希表的开销。我的问题是,如果我有一个形如g : {node: {vertex: weight...}...}的图形,那么将其转换为基于列表的邻接矩阵的最有效方法是什么?
2个回答
3
这可能不是最有效的方法,但将您的格式转换为基于列表的邻接矩阵的简单方法可以如下所示:
g = {1:{2:.5, 3:.2}, 2:{4:.7}, 4:{5:.6, 3:.3}}
hubs = g.items() # list of nodes and outgoing vertices
size=max(map(lambda hub: max(hub[0], max(hub[1].keys())), hubs))+1 # matrix dimension is highest known node index + 1
matrix=[[None]*size for row in range(size)] # set up a matrix of the appropriate size
for node, vertices in hubs: # loop through every node in dictionary
for vertice, weight in vertices.items(): # loop through vertices
matrix[vertice][node] = weight # define adjacency of both nodes by assigning the vertice's weight
这适用于有向图,假设节点仅由以零为起点的索引表示。以下是该示例处理的图形的可视化和结果矩阵:
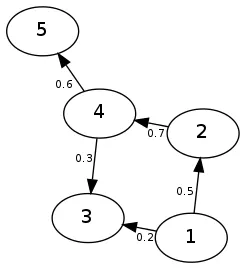
0 1 2 3 4 5
------------------------------
0 |
1 |
2 | 0.5
3 | 0.2 0.3
4 | 0.7
5 | 0.6
如果你的图实际上是无向的,我可以想到一些优化的机会。假设字典包含每个节点作为键以及列出所有顶点的情况,例如{1:{2:.2, 3:.3}, 2:{1:.2}, 3:{1:.3}},在遍历之前可以对相应的列表进行排序并限制内部循环:
hubs = sorted(g.items())
for node, vertices in hubs:
for vertice, weight in reversed(sorted(vertices.items())):
if vertice >= node:
matrix[vertice][node] = weight
matrix[node][vertice] = weight
else: # do only care about vertices that haven't been saved before,
break # continue with next node when the current one won't introduce any more vertices
您可以使用二分查找来提高效率。由于结果矩阵显然是对称的,因此您还可以进一步优化,仅存储其中一半。最简单的方法可能是在垂直轴上翻转它:
# unlike the one before, this sample doesn't rely on the dictionary containing every vertice twice
matrix=[[None]*size for row in range(size)]
for node, vertices in hubs:
for vertice, weight in vertices.items():
matrix[vertice][size-node-1] = weight
由于矩阵的一半被切掉,因此在查找节点之间的顶点时,并不是每个查询都有效,因此必须确保列的索引大于行的索引才能进行单元格查找:
u,v = sorted((u,v))
weight = matrix[v][u]
祝你好运!
- J. Katzwinkel
0
如果要在邻接表中实现,可以创建两个类,一个用于存储有关顶点信息的类。
# Vertex, which will represent each vertex in the graph.Each Vertex uses a dictionary
# to keep track of the vertices to which it is connected, and the weight of each edge.
class Vertex:
# Initialze a object of this class
# we use double underscore
def __init__(self, key):
# we identify the vertex with its key
self.id = key
# this stores the info about the various connections any object
# (vertex) of this class has using a dictionary which is called connectedTo.
# initially its not connected to any other node so,
self.connectedTo={}
# Add the information about connection between vertexes into the dictionary connectedTo
def addNeighbor(self,neighbor,weight=0):
# neighbor is another vertex we update the connectedTo dictionary ( Vertex:weight )
# with the information of this new Edge, the key is the vertex and
# the edge's weight is its value. This is the new element in the dictionary
self.connectedTo[neighbor] = weight
# Return a string containing a nicely printable representation of an object.
def __str__(self):
return str(self.id) + ' connectedTo: ' + str([x.id for x in self.connectedTo])
# Return the vertex's self is connected to in a List
def getConnections(self):
return self.connectedTo.keys()
# Return the id with which we identify the vertex, its name you could say
def getId(self):
return self.id
# Return the value (weight) of the edge (or arc) between self and nbr (two vertices)
def getWeight(self,nbr):
return self.connectedTo[nbr]
从注释中可以看出,每个顶点都存储一个“键”,用于标识它, 并且它有一个字典“connectedTo”,其中包含来自该顶点的所有连接的键-权重对。连接顶点的键和边的权重。
现在我们可以使用Graph类存储这样的顶点集合,可以像这样实现:
# The Graph class contains a dictionary that maps vertex keys to vertex objects (vertlist) and a count of the number of vertices in the graph
class Graph:
def __init__(self):
self.vertList = {}
self.numVertices = 0
# Returns a vertex which was added to the graph with given key
def addVertex(self,key):
self.numVertices = self.numVertices + 1
# create a vertex object
newVertex = Vertex(key)
# set its key
self.vertList[key] = newVertex
return newVertex
# Return the vertex object corresponding to the key - n
def getVertex(self,n):
if n in self.vertList:
return self.vertList[n]
else:
return None
# Returns boolean - checks if graph contains a vertex with key n
def __contains__(self,n):
return n in self.vertList
# Add's an edge to the graph using addNeighbor method of Vertex
def addEdge(self,f,t,cost=0):
# check if the 2 vertices involved in this edge exists inside
# the graph if not they are added to the graph
# nv is the Vertex object which is part of the graph
# and has key of 'f' and 't' respectively, cost is the edge weight
if f not in self.vertList:
nv = self.addVertex(f)
if t not in self.vertList:
nv = self.addVertex(t)
# self.vertList[f] gets the vertex with f as key, we call this Vertex
# object's addNeighbor with both the weight and self.vertList[t] (the vertice with t as key)
self.vertList[f].addNeighbor(self.vertList[t], cost)
# Return the list of all key's corresponding to the vertex's in the graph
def getVertices(self):
return self.vertList.keys()
# Returns an iterator object, which contains all the Vertex's
def __iter__(self):
return iter(self.vertList.values())
在这里,我们有一个图形类,它保存了“numVertices”中顶点的数量,并具有字典“vertList”,其中包含图形中存在的键和Vertex(我们刚刚创建的类)对象。 我们可以通过调用来创建并设置图形
# Now lets make the graph
the_graph=Graph()
print "enter the number of nodes in the graph"
no_nodes=int(raw_input())
# setup the nodes
for i in range(no_nodes):
print "enter the "+str(i+1)+" Node's key"
the_graph.addVertex(raw_input())
print "enter the number of edges in the graph"
no_edges=int(raw_input())
print "enter the maximum weight possible for any of edges in the graph"
max_weight=int(raw_input())
# setup the edges
for i in range(no_edges):
print "For the "+str(i+1)+" Edge, "
print "of the 2 nodes involved in this edge \nenter the first Node's key"
node1_key=raw_input()
print "\nenter the second Node's key"
node2_key=raw_input()
print "\nenter the cost (or weight) of this edge (or arc) - an integer"
cost=int(raw_input())
# add the edge with this info
the_graph.addEdge(node1_key,node2_key,cost)
如果你想要无向图,那么添加这一行代码:
the_graph.addEdge(node2_key,node1_key,cost)
这样连接就不是从a到b,而是a到b和b到a都有连接。
同时注意上面两个类实现的缩进,可能会不正确。- Aditya P
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接