我很新手地开始学习Python,因此想要创建一个基于文件名的HTML表格。 以下是需要处理的文件:
apple.good.2.svg
apple.good.1.svg
banana.1.ugly.svg
banana.bad.2.svg
kiwi.good.svg
对象种类总是在第一个点之前,质量属性则在名称的某个位置。
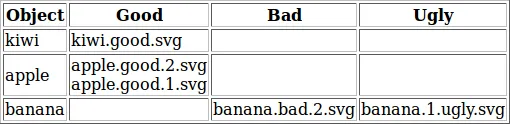
我的结果表应该如下所示:
Object Name | good | bad | ugly
-------------------------------------------------------------------------
apple | apple.good.1.svg |
| apple.good.2.svg |
-------------------------------------------------------------------------
banana | | banana.bad.2.svg | banana.1.ugly.svg
-------------------------------------------------------------------------
kiwi | kiwi.good.svg
-------------------------------------------------------------------------
这是我迄今为止所做的内容。
#!/usr/bin/python
import glob
from collections import defaultdict
fileNames = defaultdict(list)
# fill sorted list of tables based on svg filenames
svgFiles = sorted(glob.glob('*.svg'))
for s in svgFiles:
fileNames[s.split('.', 1)[0]].append(s)
# write to html
html = '<html><table border="1"><tr><th>A</th><th>' + '</th><th>'.join(dict(fileNames).keys()) + '</th></tr>'
for row in zip(*dict(fileNames).values()):
html += '<tr><td>Object Name</td><td>' + '</td><td>'.join(row) + '</td></tr>'
html += '</table></html>'
file_ = open('result.html', 'w')
file_.write(html)
file_.close()
我成功地将文件按字典顺序读取:
{'kiwi': ['kiwi.good.svg'], 'apple': ['apple.good.2.svg', 'apple.good.1.svg'], 'banana': ['banana.1.ugly.svg', 'banana.bad.2.svg']}
但是在生成HTML表格时失败了。

我该如何构建如上所示的HTML表格?其中对象写入行的第一列,文件名根据其质量属性写入列中。
medium_bad替换为medium-bad之前,也许它会起作用吗? - Anatol<img src='kiwi.goog.svg'>,我应该在哪里做这个?抱歉,如我所述,我刚开始学习 Python,也许这是一个太难的事情。 - Anatolby_state =,但不幸的是没有成功。 - Anatol