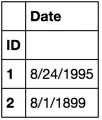
我有一个简化的数据框:
ID, Date
1 8/24/1995
2 8/1/1899 :00
我该如何运用pandas的功能,以识别数据框中任何具有额外的:00并去除它。
有什么好的解决方法吗?
我尝试了以下语法但没有成功:
df[df["Date"].str.replace(to_replace="\s:00", value="")]
输出应该是这样的:
ID, Date
1 8/24/1995
2 8/1/1899
您需要将经过修剪的列重新分配回原始列,而不是进行子集操作,另外 str.replace 方法似乎没有 to_replace 和 value 参数。相反,它具有 pat 和 repl 参数:
df["Date"] = df["Date"].str.replace("\s:00", "")
df
# ID Date
#0 1 8/24/1995
#1 2 8/1/1899
stack然后unstack。df.stack().str.replace(r'\s:00', '').unstack()
def dfreplace(df, *args, **kwargs):
s = pd.Series(df.values.flatten())
s = s.str.replace(*args, **kwargs)
return pd.DataFrame(s.values.reshape(df.shape), df.index, df.columns)
df = pd.DataFrame(['8/24/1995', '8/1/1899 :00'], pd.Index([1, 2], name='ID'), ['Date'])
dfreplace(df, '\s:00', '')
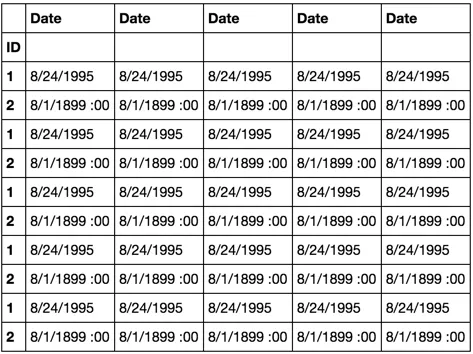
rng = range(5)
df2 = pd.concat([pd.concat([df for _ in rng]) for _ in rng], axis=1)
df2
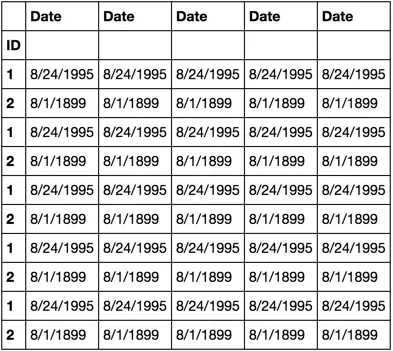
dfreplace(df2, '\s:00', '')
pd.read.csv()将一个 .csv 文件读取为数据框,但是我注意到有些日期在读取为数据框之前实际上带有多余的:00。 - MEhsan