我们知道BERT的令牌最大长度限制为512,因此如果一篇文章的长度超过了512个令牌,比如文本中有10000个令牌,那么如何使用BERT呢?
10个回答
54
你有三个基本选项:
- 你可以将较长的文本截断,仅使用前512个标记。原始的BERT实现(可能也包括其他实现)会自动截断较长的序列。对于大多数情况来说,这个选项已经足够了。
- 你可以将文本分成多个子文本,对每个子文本进行分类,然后将结果组合在一起(例如选择被大多数子文本预测为某个类别的类别)。这个选项显然更加耗费资源。
- 你甚至可以像第二个选项一样,将每个子文本的输出标记馈送到另一个网络中(但你将无法微调),具体请参见此讨论。
- chefhose
3
我计划使用BERT作为段落编码器,然后将其馈送到LSTM中,这可行吗? - user1337896
https://stackoverflow.com/questions/58703885/how-to-implement-network-using-bert-as-a-paragraph-encoder-in-long-text-classifi - user1337896
5根据我的经验,当需要分析大段落时,最好只考虑最后的512个单词,因为它们通常是最具信息量的(通常是结论)。但我认为这在很大程度上取决于所处理领域和文本。
此外,这里介绍的发送选项对我来说也不太有效,因为我正在处理对话文本,个别句子对分类作用较小。 - Anoyz
30
本文比较了几种不同的策略:如何微调BERT进行文本分类?。在IMDb电影评论数据集中,他们发现切掉文本的中间部分(而不是截取开头或结尾)效果最好!它甚至胜过了更复杂的“分层”方法,涉及将文章分成块,然后重新组合结果。
另外,我也以维基百科个人攻击数据集为例,应用了BERT,并发现简单的截断已经足够好,不需要尝试其他方法 :)
- chrismcc
16
除了将数据划分成块并传递给BERT之外,还要尝试以下新方法。
有针对长文档分析的新研究。如您所询问的,类似于预训练变压器BERT的一个新的预训练变压器Longformer最近由ALLEN NLP发布(https://arxiv.org/abs/2004.05150)。请查看此链接以获取论文。
相关工作部分还提到了一些关于长序列的先前工作。也可以在谷歌上搜索这些工作。我建议至少要阅读Transformer XL (https://arxiv.org/abs/1901.02860)。据我所知,这是长序列的最初模型之一,因此在进入“Longformers”之前,使用它作为基础会很有帮助。
有针对长文档分析的新研究。如您所询问的,类似于预训练变压器BERT的一个新的预训练变压器Longformer最近由ALLEN NLP发布(https://arxiv.org/abs/2004.05150)。请查看此链接以获取论文。
相关工作部分还提到了一些关于长序列的先前工作。也可以在谷歌上搜索这些工作。我建议至少要阅读Transformer XL (https://arxiv.org/abs/1901.02860)。据我所知,这是长序列的最初模型之一,因此在进入“Longformers”之前,使用它作为基础会很有帮助。
- Gandharv Suri
16
您可以利用HuggingFace Transformers库,其中包括以下可处理长文本(超过512个标记)的Transformer列表:
- Reformer:将Transformer的建模能力与可以有效执行长序列的架构相结合。 - Longformer:具有线性缩放序列长度的注意机制,使其易于处理数千个标记或更长的文档。
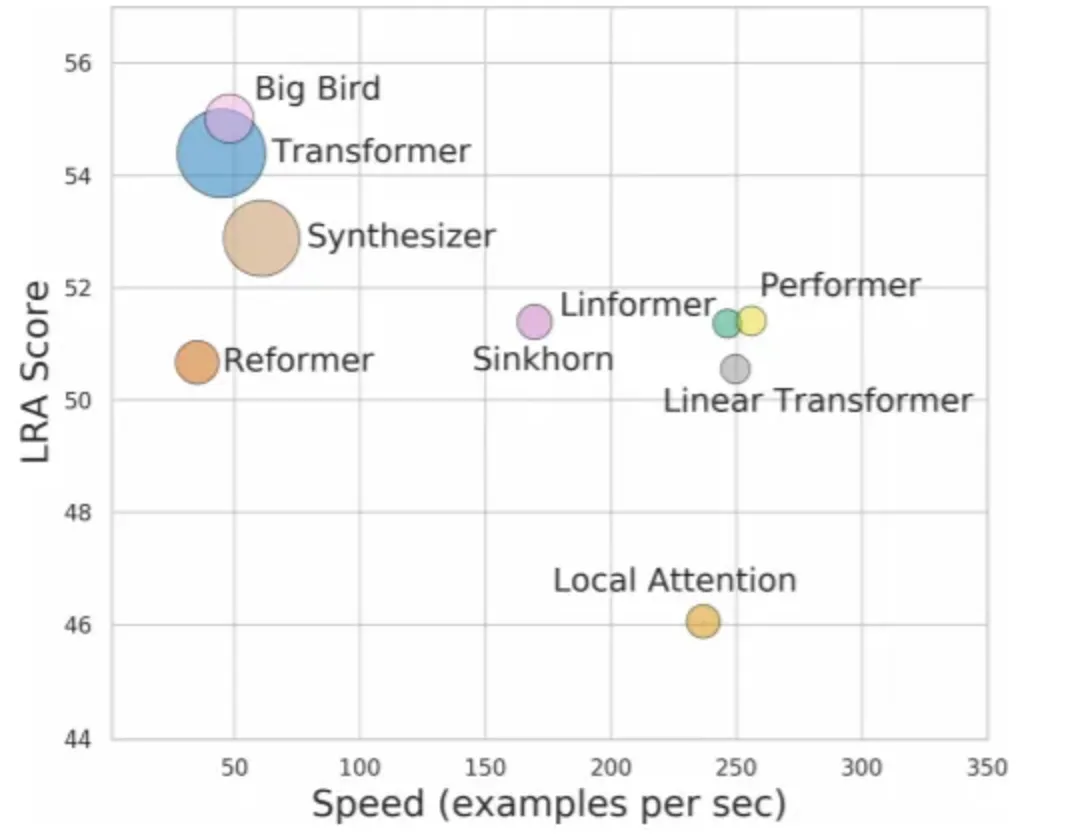
另外还有8种最近提出的高效Transformer模型,包括Sparse Transformers(Child等,2019)、Linformer(Wang等,2020)、Sinkhorn Transformers(Tay等,2020b)、Performers(Choromanski等,2020b)、Synthesizers(Tay等,2020a)、Linear Transformers(Katharopoulos等,2020)和BigBird(Zaheer等,2020)。
来自Google Research和DeepMind作者的paper试图基于“聚合指标”对这些Transformer进行比较。
- Reformer:将Transformer的建模能力与可以有效执行长序列的架构相结合。 - Longformer:具有线性缩放序列长度的注意机制,使其易于处理数千个标记或更长的文档。
另外还有8种最近提出的高效Transformer模型,包括Sparse Transformers(Child等,2019)、Linformer(Wang等,2020)、Sinkhorn Transformers(Tay等,2020b)、Performers(Choromanski等,2020b)、Synthesizers(Tay等,2020a)、Linear Transformers(Katharopoulos等,2020)和BigBird(Zaheer等,2020)。
来自Google Research和DeepMind作者的paper试图基于“聚合指标”对这些Transformer进行比较。
- SvitlanaGA...supportsUkraine
1
6我要补充一下,Longformer(其他模型我就不确定了)仍然有4096个token的限制。 - Alexandre Pieroux
13
我最近(2021年4月)发表了一篇关于这个主题的论文,你可以在arXiv上找到它 (https://arxiv.org/abs/2104.07225)。表格1允许查看有关问题的先前方法,整篇手稿是关于长文本分类并提出了一种名为Text Guide的新方法。这种新方法声称相对于 paper (https://arxiv.org/abs/1905.05583) 中提到并使用的朴素和半朴素文本选择方法,可以提高性能。
简而言之,关于您的选项:
低计算成本:使用朴素/半朴素的方法选择原始文本实例的一部分。例如选择前n个标记,或者编译一个由原始文本实例的开头和结尾组成的新文本实例。
中高计算成本:使用最近的变形金刚模型(如Longformer),其具有4096个令牌限制而不是512个。在某些情况下,这将允许覆盖整个文本实例,并且修改后的注意机制会减少计算成本。
高计算成本:将文本实例分成适合像BERT这样的模型的块,每个部分单独部署模型,然后连接生成的向量表示。
现在,在我最近发表的论文中提出了一种名为“Text Guide”的新方法。Text Guide是一种文本选择方法,与天真或半天真的截断方法相比,可以实现更好的性能。作为一种文本选择方法,Text Guide不会干扰语言模型,因此它可用于改进具有“标准”令牌限制(例如变压器模型的512个令牌)或“扩展”限制(例如Longformer模型的4096个令牌)的模型的性能。总之,Text Guide是一种低计算成本的方法,可以改善性能,优于天真和半天真的截断方法。如果文本实例超过专门为长文本分类开发的模型的限制,例如Longformer(4096个令牌),它还可以改善它们的性能。
- krzysztoffiok
4
有两种主要方法:
- 将所有“短”BERT串联在一起(最多包含512个标记)
- 构建一个真正的长BERT(CogLTX、Blockwise BERT、Longformer、Big Bird)
- François - Hoa LE
2
这篇论文《防御神经网络虚假新闻》(https://arxiv.org/abs/1905.12616)采用了一种方法。
他们的生成模型输出1024个标记,并且想要使用BERT来区分人类和机器生成的结果。他们通过初始化512个嵌入并在微调BERT时进行训练,扩展了BERT使用的序列长度。
- Zain Sarwar
2
你能解释一下他们做了什么吗?我看了这篇论文,不清楚他们到底做了什么。他们是在Bert本身上做了一些改变吗? - Ashish
你可以通过堆叠预先训练好的位置编码来实现这一点。请查看此链接中的源代码:https://discuss.huggingface.co/t/fine-tuning-bert-with-sequences-longer-than-512-tokens/12652/3 - Cristian Arteaga
1
一个相对直接的方法是改变输入。例如,您可以截断输入或分别分类输入的多个部分并汇总结果。然而,这样做可能会丢失一些有用的信息。
应用Bert于长文本的主要障碍是注意力需要 O(n ^ 2)操作以进行n输入标记。一些更新的方法试图微调Bert的架构,并使其适用于较长的文本。例如,Longformer将注意跨度限制为固定值,因此每个标记仅与一组附近的标记相关联。这张表格(Longformer 2020,Iz Beltagy等人)展示了一组基于注意力的长文本分类模型:
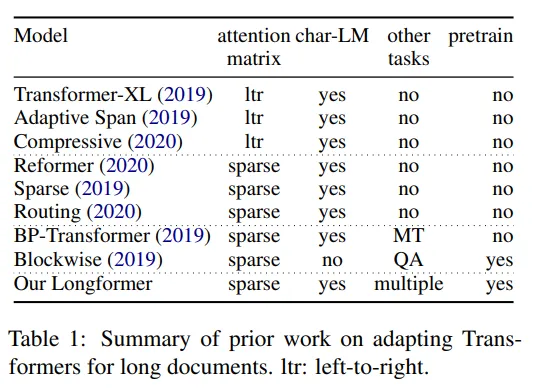
LTR(从左到右)方法按块处理输入,适用于自回归应用程序。稀疏方法主要通过避免全二次注意力矩阵计算将计算顺序降低到O(n)。
- teshnizi
0
Tokens 512 是默认 BERT 架构的最佳参数。所以最好的概念是你可以修改 BERT 的架构。有两种 BERT base 和 BERT large。
- Subhanshuja
0
在下载BERT模型到您的内核时,可以使用配置中的max_position_embeddings参数。使用此参数,您可以选择512、1024或2048作为最大序列长度。
max_position_embeddings(int,可选,默认为512)-此模型可能使用的最大序列长度。通常将其设置为较大的值以防万一(例如512或1024或2048)。
- Siva
1
1是的,但这意味着必须重新训练一个预训练模型,因为一些权重没有从模型检查点初始化,并且是新初始化的,因为形状不匹配,所以计算量更大。这肯定是一个选项,但我认为这不是最好的选择,特别是如果某人的计算能力有限。 - Federico Scaltriti
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接