你可以创建一个
索引视图,其中包含范围内每个
代码/日期 的一行。
ProductDate (indexed view)
code value date
10905 13 2005-01-01
10905 13 2005-01-02
10905 13 ...
10905 13 2016-12-31
10905 11 2017-01-01
10905 11 2017-01-02
10905 11 ...
10905 11 Today
像这样:
create schema digits
go
create table digits.Ones (digit tinyint not null primary key)
insert into digits.Ones (digit) values (0),(1),(2),(3),(4),(5),(6),(7),(8),(9)
create table digits.Tens (digit tinyint not null primary key)
insert into digits.Tens (digit) values (0),(1),(2),(3),(4),(5),(6),(7),(8),(9)
create table digits.Hundreds (digit tinyint not null primary key)
insert into digits.Hundreds (digit) values (0),(1),(2),(3),(4),(5),(6),(7),(8),(9)
create table digits.Thousands (digit tinyint not null primary key)
insert into digits.Thousands (digit) values (0),(1),(2),(3),(4),(5),(6),(7),(8),(9)
create table digits.TenThousands (digit tinyint not null primary key)
insert into digits.TenThousands (digit) values (0),(1),(2),(3),(4),(5),(6),(7),(8),(9)
go
create schema info
go
create table info.Products (code int not null, [value] int not null, begin_date date not null, end_date date null, primary key (code, begin_date))
insert into info.Products (code, [value], begin_date, end_date) values
(10905, 13, '2005-01-01', '2016-12-31'),
(10905, 11, '2017-01-01', null)
create table info.DateRange ([begin] date not null, [end] date not null, [singleton] bit not null default(1) check ([singleton] = 1))
insert into info.DateRange ([begin], [end]) values ((select min(begin_date) from info.Products), getdate())
go
create view info.ProductDate with schemabinding
as
select
p.code,
p.value,
dateadd(day, ones.digit + tens.digit*10 + huns.digit*100 + thos.digit*1000 + tthos.digit*10000, dr.[begin]) as [date]
from
info.DateRange as dr
cross join
digits.Ones as ones
cross join
digits.Tens as tens
cross join
digits.Hundreds as huns
cross join
digits.Thousands as thos
cross join
digits.TenThousands as tthos
join
info.Products as p on
dateadd(day, ones.digit + tens.digit*10 + huns.digit*100 + thos.digit*1000 + tthos.digit*10000, dr.[begin]) between p.begin_date and isnull(p.end_date, datefromparts(9999, 12, 31))
go
create unique clustered index idx_ProductDate on info.ProductDate ([date], code)
go
select *
from info.ProductDate with (noexpand)
where
date = '2014-01-01'
drop view info.ProductDate
drop table info.Products
drop table info.DateRange
drop table digits.Ones
drop table digits.Tens
drop table digits.Hundreds
drop table digits.Thousands
drop table digits.TenThousands
drop schema digits
drop schema info
go
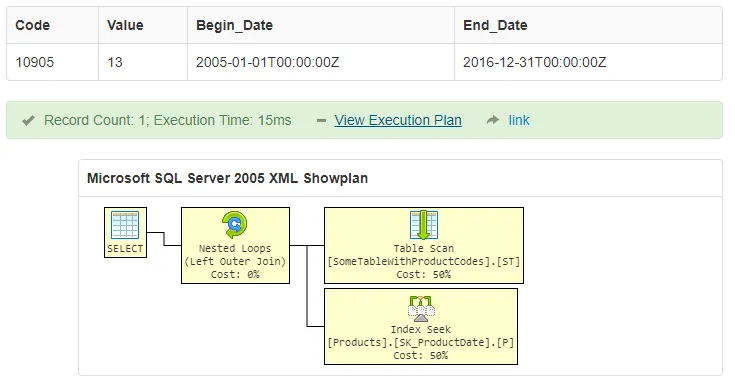
CREATE UNIQUE CLUSTERED INDEX IX_Products ON products([code], [begin_date], [end_date])这就是你需要的... - Jeroen Mostert