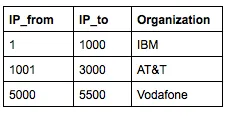
我有一个由160万个IP地址范围和组织名称组成的表格。IP地址被转换为整数。该表格的形式如下:
 我有一个包含2000个唯一IP地址(例如321223,531223等)的列表需要翻译成组织名称。
我有一个包含2000个唯一IP地址(例如321223,531223等)的列表需要翻译成组织名称。
我将翻译表作为MySQL表加载,并在IP_from和IP_to上创建索引。我循环遍历这2000个IP地址,每个IP地址运行一次查询,15分钟后报告仍在运行。我使用的查询是:
有没有更有效率的方式来进行这个批量查找?如果有好的解决方案,我可以用手指头来实现。如果有 Ruby 特定的解决方案,请告诉我,因为我正在使用 Ruby。
我有一个包含2000个唯一IP地址(例如321223,531223等)的列表需要翻译成组织名称。我将翻译表作为MySQL表加载,并在IP_from和IP_to上创建索引。我循环遍历这2000个IP地址,每个IP地址运行一次查询,15分钟后报告仍在运行。我使用的查询是:
select organization from iptable where ip_addr BETWEEN ip_start AND ip_end
有没有更有效率的方式来进行这个批量查找?如果有好的解决方案,我可以用手指头来实现。如果有 Ruby 特定的解决方案,请告诉我,因为我正在使用 Ruby。
(IP_from, IP_to)上创建一个R-Tree(空间)索引。 - eggyal