我正在使用Scikit-Learn进行多类文本分类。该数据集使用多项式朴素贝叶斯分类器进行训练,具有数百个标签。以下是适用于拟合MNB模型的Scikit Learn脚本的摘录。
from __future__ import print_function
# Read **`file.csv`** into a pandas DataFrame
import pandas as pd
path = 'data/file.csv'
merged = pd.read_csv(path, error_bad_lines=False, low_memory=False)
# define X and y using the original DataFrame
X = merged.text
y = merged.grid
# split X and y into training and testing sets;
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
# import and instantiate CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer
vect = CountVectorizer()
# create document-term matrices using CountVectorizer
X_train_dtm = vect.fit_transform(X_train)
X_test_dtm = vect.transform(X_test)
# import and instantiate MultinomialNB
from sklearn.naive_bayes import MultinomialNB
nb = MultinomialNB()
# fit a Multinomial Naive Bayes model
nb.fit(X_train_dtm, y_train)
# make class predictions
y_pred_class = nb.predict(X_test_dtm)
# generate classification report
from sklearn import metrics
print(metrics.classification_report(y_test, y_pred_class))
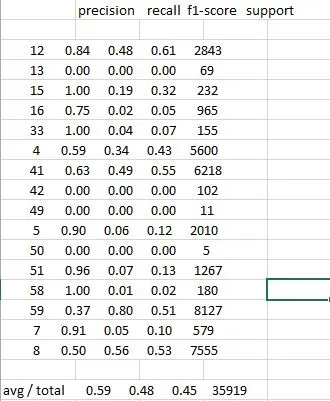
在命令行屏幕上,metrics.classification_report 的简化输出如下所示:
precision recall f1-score support
12 0.84 0.48 0.61 2843
13 0.00 0.00 0.00 69
15 1.00 0.19 0.32 232
16 0.75 0.02 0.05 965
33 1.00 0.04 0.07 155
4 0.59 0.34 0.43 5600
41 0.63 0.49 0.55 6218
42 0.00 0.00 0.00 102
49 0.00 0.00 0.00 11
5 0.90 0.06 0.12 2010
50 0.00 0.00 0.00 5
51 0.96 0.07 0.13 1267
58 1.00 0.01 0.02 180
59 0.37 0.80 0.51 8127
7 0.91 0.05 0.10 579
8 0.50 0.56 0.53 7555
avg/total 0.59 0.48 0.45 35919
我想知道是否有任何方法可以将报告输出到一个带有常规列标题的标准csv文件中。
当我将命令行输出发送到csv文件中或尝试将屏幕输出复制/粘贴到电子表格-Openoffice Calc或Excel中时,它会将结果合并为一列。看起来像这样: