我使用scikit-learn中的线性SVM(LinearSVC)解决二分类问题。我知道LinearSVC可以给出预测标签和决策得分,但我想要概率估计(标签的置信度)。我想继续使用LinearSVC因为它比带有线性核的sklearn.svm.SVC速度更快。将决策得分转换为概率估计是否可行,例如使用逻辑函数?
import sklearn.svm as suppmach
# Fit model:
svmmodel=suppmach.LinearSVC(penalty='l1',C=1)
predicted_test= svmmodel.predict(x_test)
predicted_test_scores= svmmodel.decision_function(x_test)
我想检查使用 [1 / (1 + exp(-x))] 来获取概率估计是否有意义,其中x是决策得分。
或者,是否有其他关于分类器的选项可以高效地实现这一点?
谢谢。
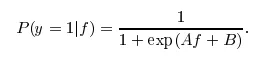
base_estimator__C,但是GridSearchCV不接受。 - Stefan Falkbase_estimator__C看起来是正确的。我建议提供一个完整的例子并在 Stack Overflow 上开一个新的问题。 - Mikhail Korobovclf时,它会导致错误,无法拟合到svm。因此我必须对两者进行训练。我认为这不会改变什么。这样正确吗? - Mattia Ducci