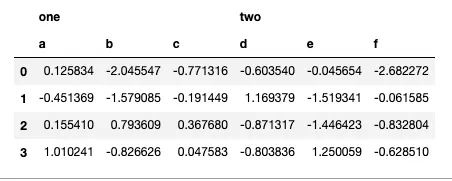
如果第二级id中的值是唯一的,则需要将掩码从一个列数据框转换为
Series。下面是使用
DataFrame.squeeze实现的可能解决方案:
np.random.seed(2019)
col = pd.MultiIndex.from_arrays([['one', '', '', 'two', 'two', 'two'],
['a', 'b', 'c', 'd', 'e', 'f']])
data = pd.DataFrame(np.random.randn(4, 6), columns=col)
print (data.xs('d', axis=1, level=1))
two
0 1.331864
1 0.953490
2 -0.189313
3 0.064969
print (data.xs('d', axis=1, level=1).squeeze())
0 1.331864
1 0.953490
2 -0.189313
3 0.064969
Name: two, dtype: float64
print (data.xs('d', axis=1, level=1).squeeze().lt(1))
0 False
1 True
2 True
3 True
Name: two, dtype: bool
df = data[data.xs('d', axis=1, level=1).squeeze().lt(1)]
使用DataFrame.iloc进行替代:
df = data[data.xs('d', axis=1, level=1).iloc[:, 0].lt(1)]
print (df)
one two
a b c d e f
1 0.573761 0.287728 -0.235634 0.953490 -1.689625 -0.344943
2 0.016905 -0.514984 0.244509 -0.189313 2.672172 0.464802
3 0.845930 -0.503542 -0.963336 0.064969 -3.205040 1.054969
如果使用
MultiIndex进行选择后,可以获取多列数据,例如这里通过
c级别进行选择:
np.random.seed(2019)
col = pd.MultiIndex.from_arrays([['one', '', '', 'two', 'two', 'two'],
['a', 'b', 'c', 'a', 'b', 'c']])
data = pd.DataFrame(np.random.randn(4, 6), columns=col)
首先使用DataFrame.xs进行选择,再用DataFrame.lt进行比较(小于号:<)。
print (data.xs('c', axis=1, level=1))
two
0 1.481278 0.685609
1 -0.235634 -0.344943
2 0.244509 0.464802
3 -0.963336 1.054969
m = data.xs('c', axis=1, level=1).lt(1)
print (m)
two
0 False True
1 True True
2 True True
3 True False
然后通过DataFrame.any测试每行是否至少有一个True,并通过布尔索引进行过滤:
df1 = data[m.any(axis=1)]
print (df1)
one two
a b c a b c
0 -0.217679 0.821455 1.481278 1.331864 -0.361865 0.685609
1 0.573761 0.287728 -0.235634 0.953490 -1.689625 -0.344943
2 0.016905 -0.514984 0.244509 -0.189313 2.672172 0.464802
3 0.845930 -0.503542 -0.963336 0.064969 -3.205040 1.054969
或者通过过滤使用DataFrame.any测试每行是否全部为True:
df1 = data[m.all(axis=1)]
print (df1)
one two
a b c a b c
1 0.573761 0.287728 -0.235634 0.953490 -1.689625 -0.344943
2 0.016905 -0.514984 0.244509 -0.189313 2.672172 0.464802