我正在从T-SQL转移我们的关系数据到图形数据库(使用Neo4j)进行GraphDB实验。我们希望处理大量数据,如果我们查询图形结构,则可以获得更好的效益。目前,即使在一些简单的WHERE子句和聚合步骤中,我们也看到了非常低的查询性能。希望能够获得一些建议,以便我们如何实现更好的性能,因为Neo4j声称可以处理十亿级别的节点。以下是我们尝试过的所有内容。
那么,让我描述这些数据: 我们拥有与客户有关的国家(地理)和产品(SKU)在线访问/购买数据。每当客户访问网站时,他的查看/购买情况将作为唯一会话ID的一部分进行跟踪,此ID在30分钟后更改。我们正在尝试通过计算不同的会话ID来准确计算一个人在网站上访问的次数。
我们拥有大约2600万行关于客户访问/购买网站时所做的数据。SQL中的数据格式如下:
问题:我们需要准确计算客户访问网站的次数。访问是按照不同的会话ID计算的。
访问计算逻辑的解释: 在上述模型中,如果我们查看一个人寻找名为“A”的SKU的访问记录,答案将是2。第一次查看在会话111中,第二次在会话222中。 同样,如果我们想知道一个人寻找SKU“ A”或“ B”时访问网站的次数,则答案也将是2。这是因为在会话111中,两个产品都被查看了,但总访问量仍然是1。会话111中有2个产品视图,但只有1次访问。因此,加上来自222的另一次访问,我们仍然有2次访问。
下面是我们建立的模型: 我们有一个事实节点,每行数据都有一个。 我们创建了不同的地理位置和产品节点,分别为400和4000。每个节点都与多个事实相关联。 类似地,我们还有不同的日期节点。
我们还为会话ID和订单ID创建了不同的节点。这两者都指向事实。 因此,我们具有以下属性的不同节点:
关系模式基于匹配属性值,看起来像这样:
这是模式的快照: 正如一些人所说,缺少索引可能导致问题,但我需要的所有索引都有,而且还有更多。我认为添加我不经常查询的额外索引不会显著降低性能。
正如一些人所说,缺少索引可能导致问题,但我需要的所有索引都有,而且还有更多。我认为添加我不经常查询的额外索引不会显著降低性能。
总共有4400万个节点,其中大部分是事实和SessionId节点。有1.31亿个关系。
如果我尝试查询识别属于约20个国家和约20个产品的人的不同访问,需要大约44秒才能获得答案。对于相同的查询(当我在Neo4j中构建索引时),SQL需要大约47秒(未使用索引)。这并不是我希望通过使用Neo4j获得的异常改进,因为我认为在SQL中建立索引会提供更好的性能。
我编写的查询类似于此:
当我使用PROFILE时,会得到大约69M的数据库查询次数: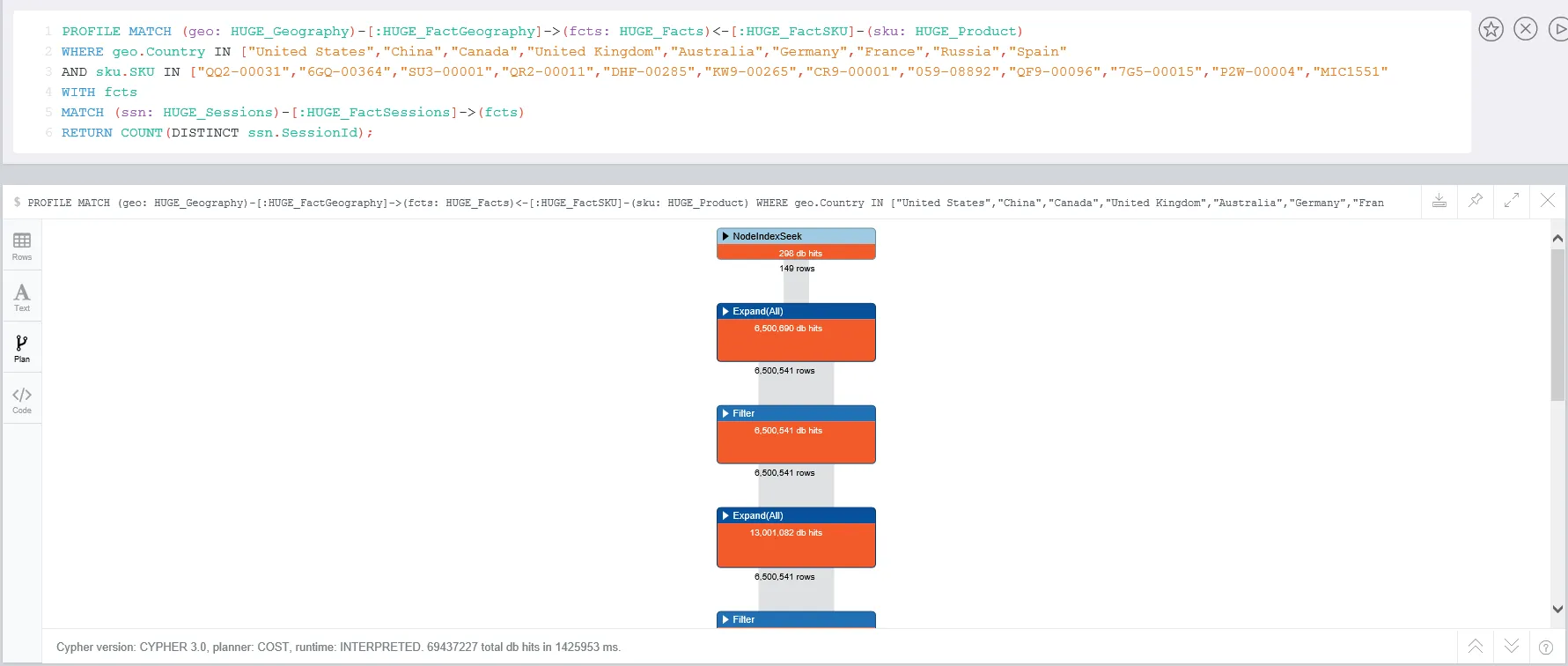 问题1:是否有方法可以改进这个模型以获得更好的查询性能?例如,我可以通过删除会话节点并仅计算Fact节点上存在的SessionIds来更改上述模型。
问题1:是否有方法可以改进这个模型以获得更好的查询性能?例如,我可以通过删除会话节点并仅计算Fact节点上存在的SessionIds来更改上述模型。
由于Fact和Session之间的节点和关系非常多,因此会出现这种情况。 因此,似乎我更愿意将SessionIds作为Facts节点的属性而受益。
当我使用PROFILE时,结果约为5000万个数据库访问次数: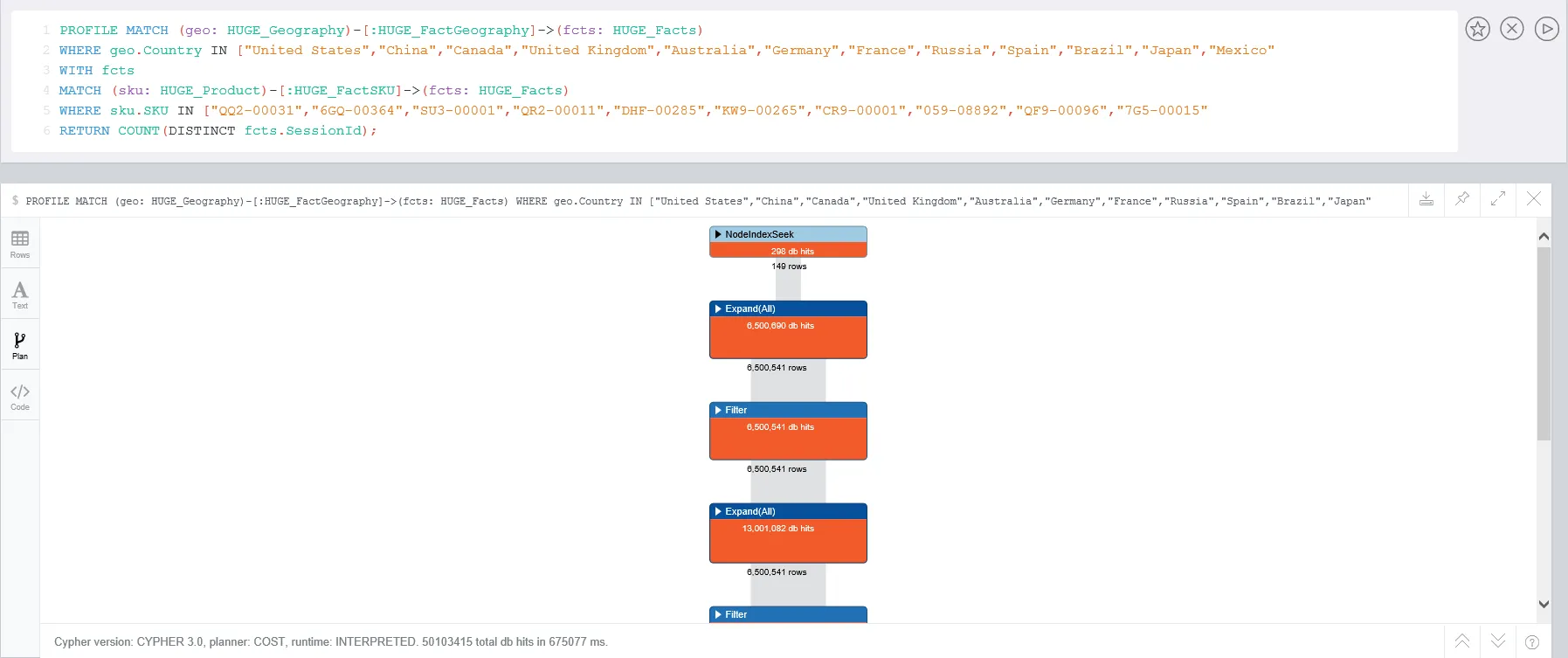 此外,有人能帮助我了解基于节点属性扫描节点变得困难的临界点吗? 当我增加节点拥有的属性数量时,是否有问题?
此外,有人能帮助我了解基于节点属性扫描节点变得困难的临界点吗? 当我增加节点拥有的属性数量时,是否有问题?
Q2)如果它需要44秒,我的Neo4j配置是否有问题? 我的Java堆有114GB RAM,但没有SSD。 我没有调整其他配置,并想知道是否可以成为瓶颈,因为我被告知Neo4j可以运行数十亿个节点?
我的机器总RAM:140GB 为Java堆分配的RAM:114GB(据我回忆,从64GB RAM移动到114GB几乎没有性能提高) 页面高速缓存大小:4GB 图形数据库大小:约45GB 我正在使用的Neo4j版本:3.0.4企业版
Q3)是否有更好的方法来制定查询以提高性能? 我尝试了以下查询:
这似乎在400个地理节点和4000个sku节点之间创建了一个交叉连接,然后测试每个关系以确定其中的160万种可能的关系组合之一是否存在。我理解得对吗?
我知道这些是长问题和非常长的帖子。但是我已经孜孜不倦地尝试了一个多星期来自己解决这些问题,并在这里分享了一些我的发现。希望社区能够指导我解决这些查询问题。先感谢您阅读该帖子!
编辑-01:Tore、Inverse和Frank,谢谢你们的帮助,希望我们能找到根本原因。
A) 我添加了一些关于我的PROFILE结果以及我的SCHEMA和Machine/Neo4j配置统计方面的详细信息。
B) 当我考虑@InverseFalcon建议的模型并尝试记住关系是更好的选择并限制关系数量时,我在微调Inverse的模型,因为我认为我们可能能够将其减少一些。以下是我制定的模型:
现在这两个模型都有优势。在第一个模型中,我将SKU作为不同的节点进行维护,并且有不同的关系来确定是购买还是查看。
在第二个模型中,我完全删除了SKU节点,并将它们作为关系添加。我知道这会导致很多关系,但是关系的数量仍然很小,因为我们也要丢弃所有要删除的SKU节点和关系。 我们将通过比较SKU字符串来测试关系,这是一项密集的操作,可以通过只保留会话和地理位置节点并删除日期节点并将日期属性添加到SKU关系来避免。如下:
那么,让我描述这些数据: 我们拥有与客户有关的国家(地理)和产品(SKU)在线访问/购买数据。每当客户访问网站时,他的查看/购买情况将作为唯一会话ID的一部分进行跟踪,此ID在30分钟后更改。我们正在尝试通过计算不同的会话ID来准确计算一个人在网站上访问的次数。
我们拥有大约2600万行关于客户访问/购买网站时所做的数据。SQL中的数据格式如下:
----------------------------------------------------------------------------
| Date| SessionId| Geography| SKU| OrderId| Revenue| Units||
|--------|------------|------------|------|----------|-----------|--------||
|20160101| 111| USA| A| null| 0| 0||
|20160101| 111| USA| B| 1| 50| 1||
|20160101| 222| UK| A| 2| 10| 1||
----------------------------------------------------------------------------
问题:我们需要准确计算客户访问网站的次数。访问是按照不同的会话ID计算的。
访问计算逻辑的解释: 在上述模型中,如果我们查看一个人寻找名为“A”的SKU的访问记录,答案将是2。第一次查看在会话111中,第二次在会话222中。 同样,如果我们想知道一个人寻找SKU“ A”或“ B”时访问网站的次数,则答案也将是2。这是因为在会话111中,两个产品都被查看了,但总访问量仍然是1。会话111中有2个产品视图,但只有1次访问。因此,加上来自222的另一次访问,我们仍然有2次访问。
下面是我们建立的模型: 我们有一个事实节点,每行数据都有一个。 我们创建了不同的地理位置和产品节点,分别为400和4000。每个节点都与多个事实相关联。 类似地,我们还有不同的日期节点。
我们还为会话ID和订单ID创建了不同的节点。这两者都指向事实。 因此,我们具有以下属性的不同节点:
1) Geography {Locale, Country}
2) SKU {SKU, ProductName}
3) Date {Date}
4) Sessions {SessionIds}
5) Orders {OrderIds}
6) Facts {Locale, Country, SKU, ProductName, Date, SessionIds, OrderIds}
关系模式基于匹配属性值,看起来像这样:
(:Geography)-[:FactGeo]->(:Facts)
(:SKU)-[:FactSKU]->(:Facts]
(:Date)-[:FactDate]->(:Facts)
(:SessionId)-[:FactSessions]->(:Facts)
(:OrderId)-[:FactOrders]->(:Facts)
这是模式的快照:
正如一些人所说,缺少索引可能导致问题,但我需要的所有索引都有,而且还有更多。我认为添加我不经常查询的额外索引不会显著降低性能。总共有4400万个节点,其中大部分是事实和SessionId节点。有1.31亿个关系。
如果我尝试查询识别属于约20个国家和约20个产品的人的不同访问,需要大约44秒才能获得答案。对于相同的查询(当我在Neo4j中构建索引时),SQL需要大约47秒(未使用索引)。这并不是我希望通过使用Neo4j获得的异常改进,因为我认为在SQL中建立索引会提供更好的性能。
我编写的查询类似于此:
(geo: Geography)-[:FactGeo]->(fct: Facts)<-(sku: SKU)
WHERE geo.Country IN ["US", "India", "UK"...]
AND sku.SKU IN ["A","B","C".....]
MATCH (ssn: Sessions)-[:FactSessions]->(fct)
RETURN COUNT(DISTINCT ssn.SessionId);
当我使用PROFILE时,会得到大约69M的数据库查询次数:
问题1:是否有方法可以改进这个模型以获得更好的查询性能?例如,我可以通过删除会话节点并仅计算Fact节点上存在的SessionIds来更改上述模型。(geo: Geography)-[:FactGeo]->(fct: Facts)<-(sku: SKU)
WHERE geo.Country IN ["US", "India", "UK"...]
AND sku.SKU IN ["A","B","C".....]
RETURN COUNT(DISTINCT fct.SessionId);
由于Fact和Session之间的节点和关系非常多,因此会出现这种情况。 因此,似乎我更愿意将SessionIds作为Facts节点的属性而受益。
当我使用PROFILE时,结果约为5000万个数据库访问次数:
此外,有人能帮助我了解基于节点属性扫描节点变得困难的临界点吗? 当我增加节点拥有的属性数量时,是否有问题?Q2)如果它需要44秒,我的Neo4j配置是否有问题? 我的Java堆有114GB RAM,但没有SSD。 我没有调整其他配置,并想知道是否可以成为瓶颈,因为我被告知Neo4j可以运行数十亿个节点?
我的机器总RAM:140GB 为Java堆分配的RAM:114GB(据我回忆,从64GB RAM移动到114GB几乎没有性能提高) 页面高速缓存大小:4GB 图形数据库大小:约45GB 我正在使用的Neo4j版本:3.0.4企业版
Q3)是否有更好的方法来制定查询以提高性能? 我尝试了以下查询:
(geo: Geography)-[:FactGeo]->(fct: Facts)
WHERE geo.Country IN ["US", "India", "UK"...]
MATCH (sku: SKU)-[:FactSKU]->(fct)
WHERE sku.SKU IN ["A","B","C".....]
RETURN COUNT(DISTINCT fct.SessionId);
然而,它提供的性能与Q1中略有改进的查询相当,并记录了相同数量的DBhits。
当我使用PROFILE时,这导致约50M个db hits,与Q1中的查询完全相同:
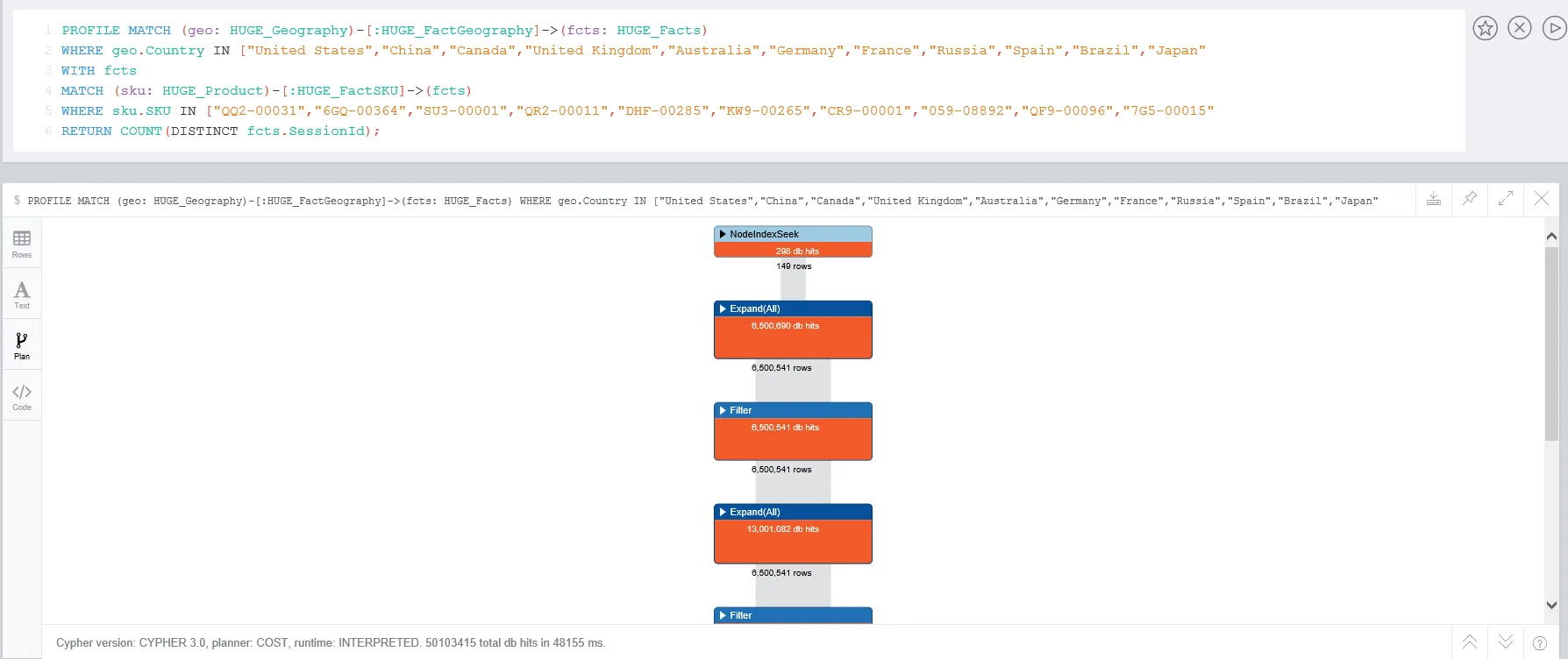
Q4)如果我将我的查询从Q3修改为以下内容,而不是看到改进,我会看到性能大幅下降:
MATCH (geo: Geography)
WHERE geo.Country IN ["US", "India", "UK"...]
WITH geo
MATCH (sku: SKU)
WHERE sku.SKU IN ["A","B","C".....]
WITH geo, sku
MATCH (geo)-[:FactGeo]->(fct: Facts)<-[:FactSKU]-(sku)
RETURN COUNT(DISTINCT fct.SessionId);
这似乎在400个地理节点和4000个sku节点之间创建了一个交叉连接,然后测试每个关系以确定其中的160万种可能的关系组合之一是否存在。我理解得对吗?
我知道这些是长问题和非常长的帖子。但是我已经孜孜不倦地尝试了一个多星期来自己解决这些问题,并在这里分享了一些我的发现。希望社区能够指导我解决这些查询问题。先感谢您阅读该帖子!
编辑-01:Tore、Inverse和Frank,谢谢你们的帮助,希望我们能找到根本原因。
A) 我添加了一些关于我的PROFILE结果以及我的SCHEMA和Machine/Neo4j配置统计方面的详细信息。
B) 当我考虑@InverseFalcon建议的模型并尝试记住关系是更好的选择并限制关系数量时,我在微调Inverse的模型,因为我认为我们可能能够将其减少一些。以下是我制定的模型:
(:Session)-[:ON]->(:Date)
(:Session)-[:IN]->(:Geography)
(:Session)-[:Viewed]->(:SKU)
(:Session)-[:Bought]->(:SKU)
或者
(:Session)-[:ON]->(:Date)
(:Session)-[:IN {SKU: "A", HasViewedOrBought: 1}]->(:Geography)
现在这两个模型都有优势。在第一个模型中,我将SKU作为不同的节点进行维护,并且有不同的关系来确定是购买还是查看。
在第二个模型中,我完全删除了SKU节点,并将它们作为关系添加。我知道这会导致很多关系,但是关系的数量仍然很小,因为我们也要丢弃所有要删除的SKU节点和关系。 我们将通过比较SKU字符串来测试关系,这是一项密集的操作,可以通过只保留会话和地理位置节点并删除日期节点并将日期属性添加到SKU关系来避免。如下:
(:Session)-[:ON]->(:Date)
(:Session)-[:IN {Date: {"2016-01-01"}, SKU: "A", HasViewedOrBought: 1}]->(:Geography)
但是,如果我要基于两个字符串属性来测试地理和SKU节点之间的关系,那么我将需要进行测试。(可以说日期可以转换为整数,但仍然存在另一种模型之间的对决)
C) @Tore,感谢您解释并确认了我的对Q4的理解。但是,如果GraphDB执行这样的计算,即连接并比较每个关系与该连接是否相同,它实际上不是以RDBMS应该具有的方式工作吗? 它未能利用应该易于找到直接路径的图形遍历,这对我来说似乎是一种糟糕的实现?