我目前正在使用CUDA 5.0中引入的新的CUDA动态并行性(CDP)功能进行尝试。我选择N-queens puzzle作为树搜索算法的例子,这种算法具有高工作不平衡性,我认为CDP可能会从中受益。
我的方法大致如下:对于给定的棋盘配置(一个带有一定数量皇后已经放置在第一行的棋盘),我启动了一个带有多个线程的内核。每个线程尝试下面给定最大深度的子树中的一个可能分支。如果分支的叶子仍然表示一个有效的配置,则该线程会生成一个子网格线程,用于搜索基于该配置的子树。找到其配置无效(两个或更多个皇后可以互相攻击)的线程将终止。如果线程成功地将最后一个皇后放在了棋盘上,则它将增加解决方案计数器。
在启动内核之前,我在CPU上预先计算了一些棋盘配置,然后为每个配置启动了一个网格。
现在问题来了:我发现我的解决方案比另一个不使用CDP的CUDA实现要慢得多。因此,我启动了Nsisght分析器以找出原因。以下是我的第一个结果(当N=10时):
但情况变得更加奇怪了。当我将 N(因此工作量)增加到 13 时,模式如下所示:
我的方法大致如下:对于给定的棋盘配置(一个带有一定数量皇后已经放置在第一行的棋盘),我启动了一个带有多个线程的内核。每个线程尝试下面给定最大深度的子树中的一个可能分支。如果分支的叶子仍然表示一个有效的配置,则该线程会生成一个子网格线程,用于搜索基于该配置的子树。找到其配置无效(两个或更多个皇后可以互相攻击)的线程将终止。如果线程成功地将最后一个皇后放在了棋盘上,则它将增加解决方案计数器。
在启动内核之前,我在CPU上预先计算了一些棋盘配置,然后为每个配置启动了一个网格。
现在问题来了:我发现我的解决方案比另一个不使用CDP的CUDA实现要慢得多。因此,我启动了Nsisght分析器以找出原因。以下是我的第一个结果(当N=10时):
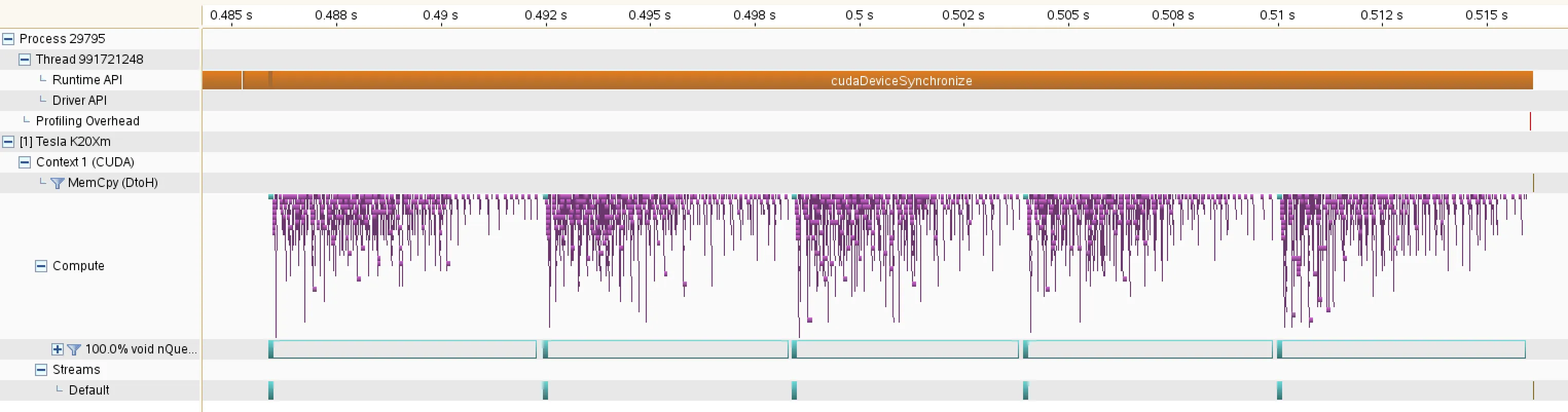
显然GPU没有完全占用。因此,我认为我需要使用不同的流来启动子网格,以防止它们相互等待。下面是使用每个子网格启动新流时的分析结果:
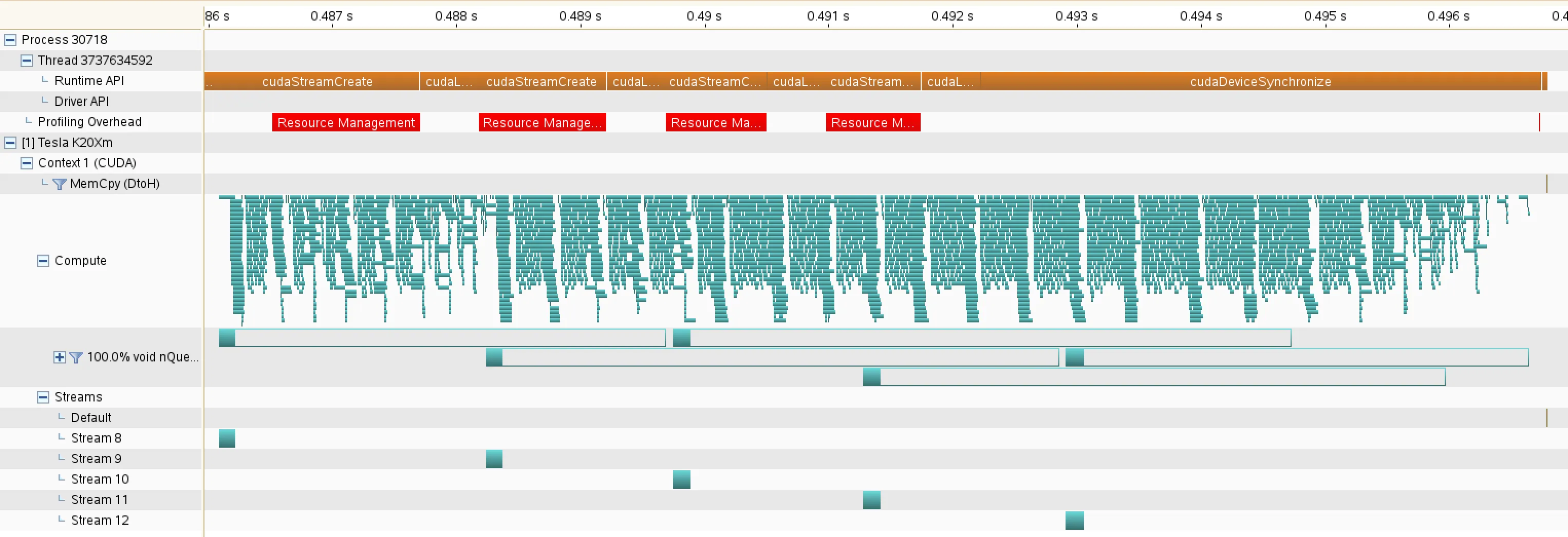
但情况变得更加奇怪了。当我将 N(因此工作量)增加到 13 时,模式如下所示:
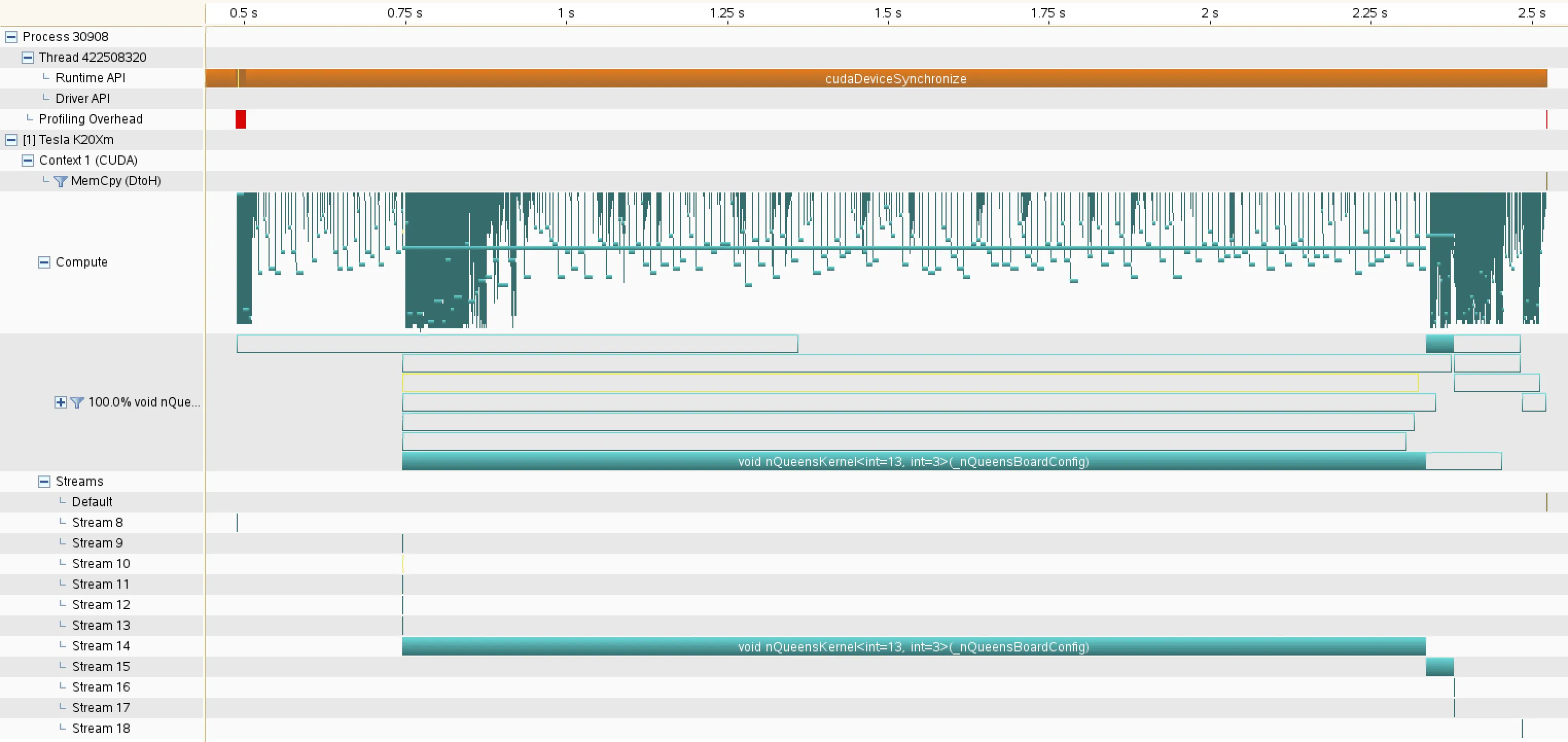
有人知道CDP的内部工作原理吗?我是否没有考虑到任何隐式同步屏障?或者我是否错误地阅读了分析器输出?我特别想知道在最后一种情况下几乎涵盖整个执行时间的这个线程可能是什么。
我还没有找到关于Nsight Visual Profiler有关CDP输出的文档。任何关于Nsight所显示内容的好参考资料也会有所帮助。
谢谢!