我们在使用CUDA动态并行性时遇到了性能问题。目前,CDP的性能至少比传统方法慢3倍。
我们编写了最简单的可重现代码来展示这个问题,即将数组中所有元素的值增加1。例如:
从图片中可以看出,在动态并行方法中,父内核在两个子内核完成后花费了过多的时间才关闭,这是导致执行时间增加3倍或4倍的原因。即使考虑最坏情况,如果所有三个内核(父内核和两个子内核)按顺序运行,所需时间也应少得多。即每个内核有N/3的工作量,整个父内核应该只需要大约3个子内核的时间,这要少得多。是否有办法解决这个问题?
编辑:罗伯特·克罗维拉在评论中已经解释了子内核的串行现象,以及方法2的情况(非常感谢)。事实上,内核确实按顺序运行,并不会无效地描述粗体文本中的问题(至少暂时不会)。
我们编写了最简单的可重现代码来展示这个问题,即将数组中所有元素的值增加1。例如:
a[0,0,0,0,0,0,0,.....,0] --> kernel +1 --> a[1,1,1,1,1,1,1,1,1]
这个简单示例的目的只是为了看看CDP是否能像其他工具一样执行,或者是否存在严重的开销。
代码在这里:
#include <stdio.h>
#include <cuda.h>
#define BLOCKSIZE 512
__global__ void kernel_parent(int *a, int n, int N);
__global__ void kernel_simple(int *a, int n, int N, int offset);
// N is the total array size
// n is the worksize for a kernel (one third of N)
__global__ void kernel_parent(int *a, int n, int N){
cudaStream_t s1, s2;
cudaStreamCreateWithFlags(&s1, cudaStreamNonBlocking);
cudaStreamCreateWithFlags(&s2, cudaStreamNonBlocking);
int tid = blockIdx.x * blockDim.x + threadIdx.x;
if(tid == 0){
dim3 block(BLOCKSIZE, 1, 1);
dim3 grid( (n + BLOCKSIZE - 1)/BLOCKSIZE, 1, 1);
kernel_simple<<< grid, block, 0, s1 >>> (a, n, N, n);
kernel_simple<<< grid, block, 0, s2 >>> (a, n, N, 2*n);
}
a[tid] += 1;
}
__global__ void kernel_simple(int *a, int n, int N, int offset){
int tid = blockIdx.x * blockDim.x + threadIdx.x;
int pos = tid + offset;
if(pos < N){
a[pos] += 1;
}
}
int main(int argc, char **argv){
if(argc != 3){
fprintf(stderr, "run as ./prog n method\nn multiple of 32 eg: 1024, 1048576 (1024^2), 4194304 (2048^2), 16777216 (4096^2)\nmethod:\n0 (traditional) \n1 (dynamic parallelism)\n2 (three kernels using unique streams)\n");
exit(EXIT_FAILURE);
}
int N = atoi(argv[1])*3;
int method = atoi(argv[2]);
// init array as 0
int *ah, *ad;
printf("genarray of 3*N = %i.......", N); fflush(stdout);
ah = (int*)malloc(sizeof(int)*N);
for(int i=0; i<N; ++i){
ah[i] = 0;
}
printf("done\n"); fflush(stdout);
// malloc and copy array to gpu
printf("cudaMemcpy:Host->Device..........", N); fflush(stdout);
cudaMalloc(&ad, sizeof(int)*N);
cudaMemcpy(ad, ah, sizeof(int)*N, cudaMemcpyHostToDevice);
printf("done\n"); fflush(stdout);
// kernel launch (timed)
cudaStream_t s1, s2, s3;
cudaStreamCreateWithFlags(&s1, cudaStreamNonBlocking);
cudaStreamCreateWithFlags(&s2, cudaStreamNonBlocking);
cudaStreamCreateWithFlags(&s3, cudaStreamNonBlocking);
cudaEvent_t start, stop;
float rtime = 0.0f;
cudaEventCreate(&start);
cudaEventCreate(&stop);
printf("Kernel...........................", N); fflush(stdout);
if(method == 0){
// CLASSIC KERNEL LAUNCH
dim3 block(BLOCKSIZE, 1, 1);
dim3 grid( (N + BLOCKSIZE - 1)/BLOCKSIZE, 1, 1);
cudaEventRecord(start, 0);
kernel_simple<<< grid, block >>> (ad, N, N, 0);
cudaDeviceSynchronize();
cudaEventRecord(stop, 0);
}
else if(method == 1){
// DYNAMIC PARALLELISM
dim3 block(BLOCKSIZE, 1, 1);
dim3 grid( (N/3 + BLOCKSIZE - 1)/BLOCKSIZE, 1, 1);
cudaEventRecord(start, 0);
kernel_parent<<< grid, block, 0, s1 >>> (ad, N/3, N);
cudaDeviceSynchronize();
cudaEventRecord(stop, 0);
}
else{
// THREE CONCURRENT KERNEL LAUNCHES USING STREAMS
dim3 block(BLOCKSIZE, 1, 1);
dim3 grid( (N/3 + BLOCKSIZE - 1)/BLOCKSIZE, 1, 1);
cudaEventRecord(start, 0);
kernel_simple<<< grid, block, 0, s1 >>> (ad, N/3, N, 0);
kernel_simple<<< grid, block, 0, s2 >>> (ad, N/3, N, N/3);
kernel_simple<<< grid, block, 0, s3 >>> (ad, N/3, N, 2*(N/3));
cudaDeviceSynchronize();
cudaEventRecord(stop, 0);
}
printf("done\n"); fflush(stdout);
printf("cudaMemcpy:Device->Host..........", N); fflush(stdout);
cudaMemcpy(ah, ad, sizeof(int)*N, cudaMemcpyDeviceToHost);
printf("done\n"); fflush(stdout);
printf("checking result.................."); fflush(stdout);
for(int i=0; i<N; ++i){
if(ah[i] != 1){
fprintf(stderr, "bad element: a[%i] = %i\n", i, ah[i]);
exit(EXIT_FAILURE);
}
}
printf("done\n"); fflush(stdout);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&rtime, start, stop);
printf("rtime: %f ms\n", rtime); fflush(stdout);
return EXIT_SUCCESS;
}
可以编译使用
nvcc -arch=sm_35 -rdc=true -lineinfo -lcudadevrt -use_fast_math main.cu -o prog
这个例子可以使用三种方法计算结果:
- 简单的核心:只有一个传统的核心+在数组上进行一次 +1 操作。
- 动态并行性:从 main() 中调用一个父核心,在范围 [0,N/3) 上进行 +1 操作,并调用两个子核心。第一个子核心在范围 [N/3, 2*N/3) 上进行 +1 操作,第二个子核心在范围 [2*N/3,N) 上进行 +1 操作。子核心使用不同的流启动,因此它们可以并发执行。
- 来自主机的三个流:这个方法只是从 main() 启动三个非阻塞流,每个流都处理数组的三分之一。
我得到了以下关于方法 0(简单核心)的概要:
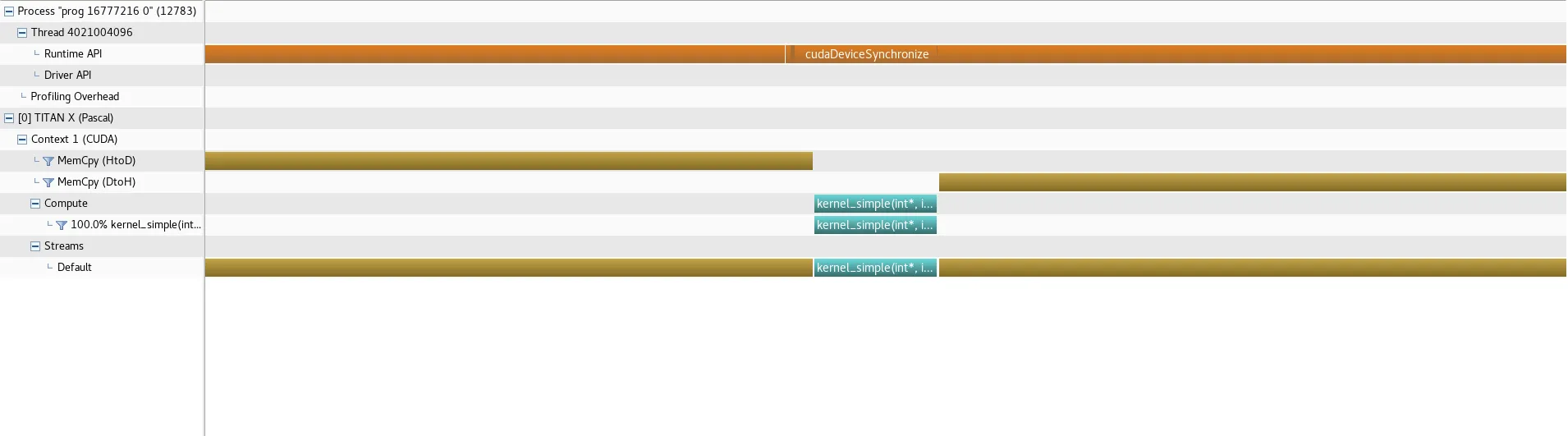 以下为方法 1(动态并行性)的概要:
以下为方法 1(动态并行性)的概要:
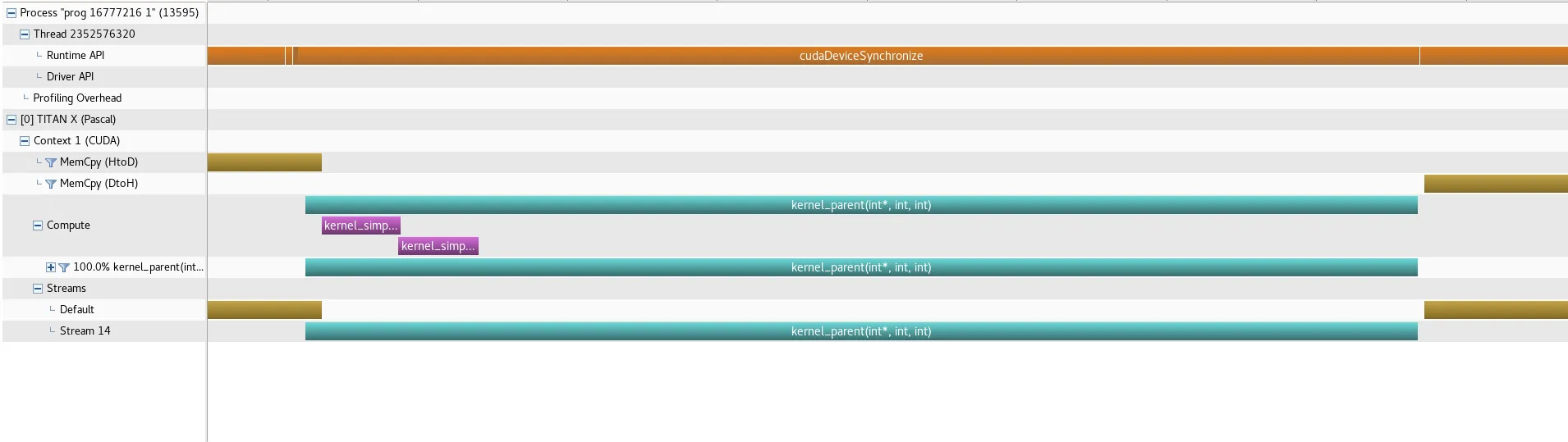 以下为方法 2(来自主机的三个流)的概要:
以下为方法 2(来自主机的三个流)的概要:
 运行时间如下:
运行时间如下:
➜ simple-cdp git:(master) ✗ ./prog 16777216 0
genarray of 3*N = 50331648.......done
cudaMemcpy:Host->Device..........done
Kernel...........................done
cudaMemcpy:Device->Host..........done
checking result..................done
rtime: 1.140928 ms
➜ simple-cdp git:(master) ✗ ./prog 16777216 1
genarray of 3*N = 50331648.......done
cudaMemcpy:Host->Device..........done
Kernel...........................done
cudaMemcpy:Device->Host..........done
checking result..................done
rtime: 5.790048 ms
➜ simple-cdp git:(master) ✗ ./prog 16777216 2
genarray of 3*N = 50331648.......done
cudaMemcpy:Host->Device..........done
Kernel...........................done
cudaMemcpy:Device->Host..........done
checking result..................done
rtime: 1.011936 ms
从图片中可以看出,在动态并行方法中,父内核在两个子内核完成后花费了过多的时间才关闭,这是导致执行时间增加3倍或4倍的原因。即使考虑最坏情况,如果所有三个内核(父内核和两个子内核)按顺序运行,所需时间也应少得多。即每个内核有N/3的工作量,整个父内核应该只需要大约3个子内核的时间,这要少得多。是否有办法解决这个问题?
编辑:罗伯特·克罗维拉在评论中已经解释了子内核的串行现象,以及方法2的情况(非常感谢)。事实上,内核确实按顺序运行,并不会无效地描述粗体文本中的问题(至少暂时不会)。