给定一个平衡的数据集(两个类别的大小相同),将其放入SVM模型中,我得到了一个高的AUC值(约为0.9),但低准确率(约为0.5)。
我完全不知道为什么会发生这种情况,有人能为我解释一下吗?
给定一个平衡的数据集(两个类别的大小相同),将其放入SVM模型中,我得到了一个高的AUC值(约为0.9),但低准确率(约为0.5)。
我完全不知道为什么会发生这种情况,有人能为我解释一下吗?
关于ROC分析
ROC分析的一般背景是二元分类,其中分类器将一个集合中的元素分配到两个组中。这两个类通常被称为“阳性”和“阴性”。在这里,我们假设分类器可以归结为以下功能行为:
def classifier(observation, t):
if score_function(observation) <= t:
observation belongs to the "negative" class
else:
observation belongs to the "positive" class
TPR = TP / P = TP / (TP+FN) = number of true positives / number of positives
FPR = FP / N = FP / (FP+TN) = number of false positives / number of negatives
accuracy = (TP+TN)/(Total number of cases) = (TP+TN)/(TP+FP+TN+FN)
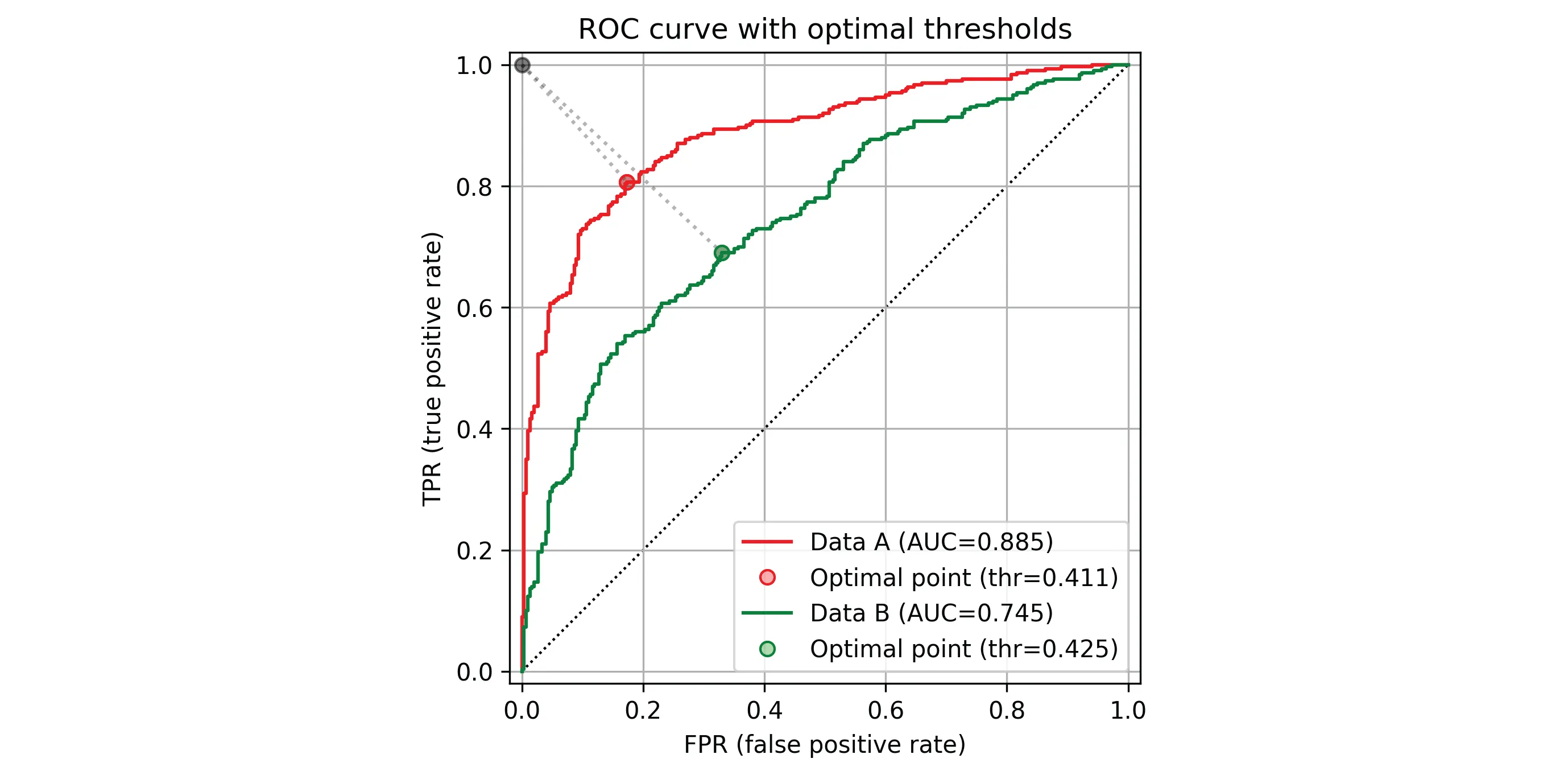
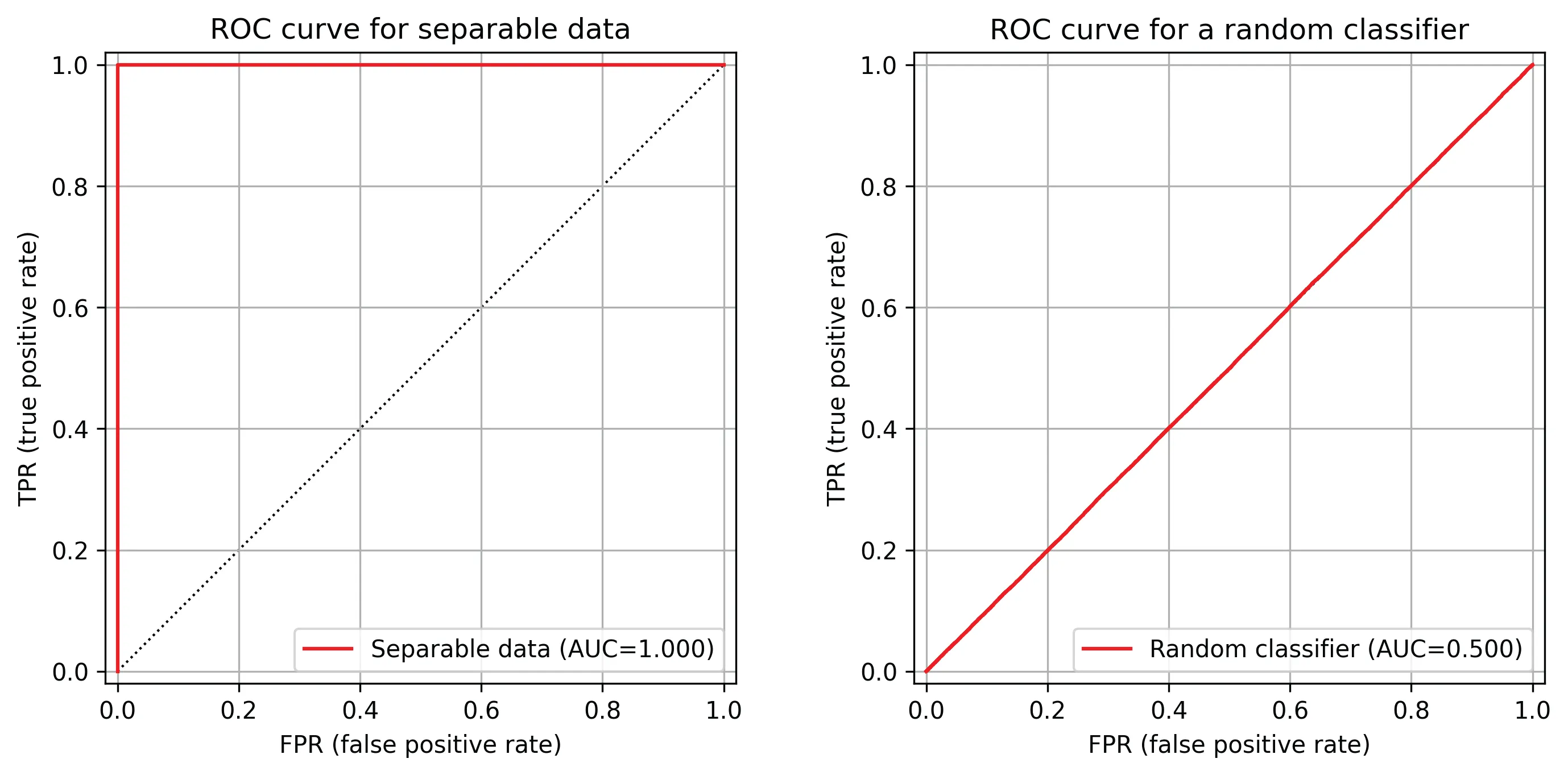
给定一个分类器和一个验证数据集,我们可以评估不同决策阈值t下的真正例率TPR(t)和假正例率FPR(t)。然后,绘制FPR(t)与TPR(t)的曲线可以得到接收者操作特征(ROC)曲线。以下是一些使用roc-utils*在Python中绘制的样本ROC曲线。
http://sandeeptata.blogspot.com/2015/04/on-dangers-of-auc.html
如果每次都发生这种情况,可能是您的模型不正确。 从kernel开始,您需要更改并尝试使用新集合来验证模型。 每次查看混淆矩阵并检查TN和TP区域。模型应该无法检测到其中之一。