我使用tf.keras通过谷歌BERT训练了一个文本分类器。
我的数据集包含50,000行数据,平均分布在5个标签上。这是一个更大数据集的子集,但我选择这些特定的标签,因为它们彼此完全不同,以尝试避免训练时的混淆。
我按照以下方式创建数据拆分:
当我运行测试数据时,将经过独热编码的标签转换回其原始标签(使用
我的数据集包含50,000行数据,平均分布在5个标签上。这是一个更大数据集的子集,但我选择这些特定的标签,因为它们彼此完全不同,以尝试避免训练时的混淆。
我按照以下方式创建数据拆分:
train, test = train_test_split(df, test_size=0.30, shuffle=True, stratify=df['label'], random_state=10)
train, val = train_test_split(train, test_size=0.1, shuffle=True, stratify=train['label'], random_state=10)
这个模型的设计如下:
def compile():
mirrored_strategy = tf.distribute.MirroredStrategy()
with mirrored_strategy.scope():
learn_rate = 4e-5
bert = 'bert-base-uncased'
model = TFBertModel.from_pretrained(bert, trainable=False)
input_ids_layer = Input(shape=(512,), dtype=np.int32)
input_mask_layer = Input(shape=(512,), dtype=np.int32)
bert_layer = model([input_ids_layer, input_mask_layer])[0]
X = tf.keras.layers.GlobalMaxPool1D()(bert_layer)
output = Dense(5)(X)
output = BatchNormalization(trainable=False)(output)
output = Activation('softmax')(output)
model_ = Model(inputs=[input_ids_layer, input_mask_layer], outputs=output)
optimizer = tf.keras.optimizers.Adam(4e-5)
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
metric = tf.keras.metrics.SparseCategoricalAccuracy('accuracy')
model_.compile(optimizer=optimizer, loss=loss, metrics=[metric])
return model_
这将得到以下结果:
loss: 1.2433
accuracy: 0.8024
val_loss: 1.2148
val_accuracy: 0.8300
f1_score: 0.8283
precision: 0.8300
recall: 0.8286
auc: 0.9676
当我运行测试数据时,将经过独热编码的标签转换回其原始标签(使用
model.load_weights())...test_sample = [test_dataset[0],test_dataset[1], test_dataset[2]]
predictions = tf.argmax(model.predict(test_sample[:2]), axis =1)
preds_inv = le.inverse_transform(predictions)
true_inv = le.inverse_transform(test_sample[2])
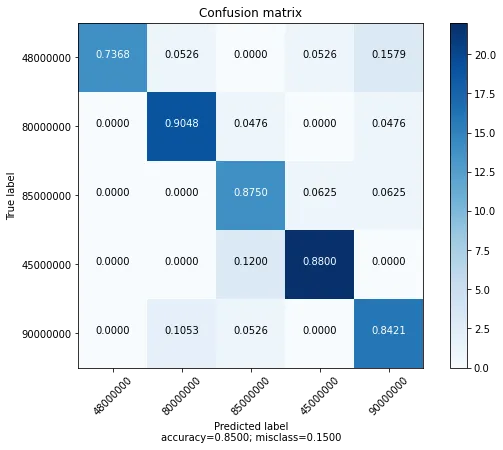
...混淆矩阵中的数值杂乱无章:
confusion_matrix(true_inv, inv_preds)
array([[ 967, 202, 7, 685, 1139],
[ 474, 785, 27, 717, 997],
[ 768, 372, 46, 1024, 790],
[ 463, 426, 27, 1272, 812],
[ 387, 224, 11, 643, 1735]])
有趣的是,第三个标签几乎不被预测。
请注意,在批量归一化中,我将trainable设置为False,但在训练期间,它会被设置为True。
输入数据由两个数组组成:文本字符串的数值向量表示(嵌入)和用于识别每个字符串的512个元素中哪些是填充值的填充令牌。
在使用深度预训练模型(BERT)对均衡数据集进行训练时,给出合理的准确度分数,但得到可怕的预测结果,可能的原因有哪些?