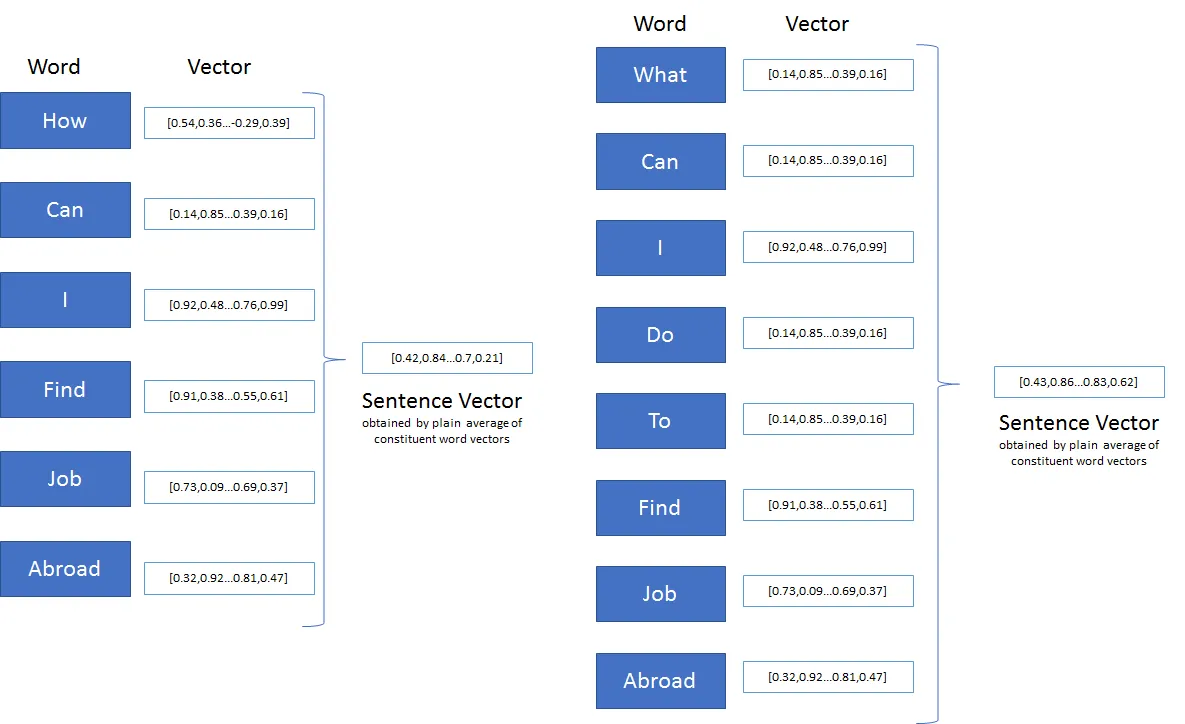
运行Spark的Word2Vec示例,我意识到它接受一个字符串数组并输出一个向量。我的问题是,它不应该返回矩阵而不是向量吗?我期望每个输入单词都有一个向量。但它只返回一个向量!
或者它应该接受字符串而不是字符串数组(一个单词)作为输入。然后,当然,它可以返回一个向量作为输出。但是接受一个字符串数组并返回一个单一的向量对我来说没有意义。
[更新]
根据@Shaido的请求,这里是代码,我进行了微小的更改以打印输出的模式:
或者它应该接受字符串而不是字符串数组(一个单词)作为输入。然后,当然,它可以返回一个向量作为输出。但是接受一个字符串数组并返回一个单一的向量对我来说没有意义。
[更新]
根据@Shaido的请求,这里是代码,我进行了微小的更改以打印输出的模式:
public class JavaWord2VecExample {
public static void main(String[] args) {
SparkSession spark = SparkSession
.builder()
.appName("JavaWord2VecExample")
.getOrCreate();
// $example on$
// Input data: Each row is a bag of words from a sentence or document.
List<Row> data = Arrays.asList(
RowFactory.create(Arrays.asList("Hi I heard about Spark".split(" "))),
RowFactory.create(Arrays.asList("I wish Java could use case classes".split(" "))),
RowFactory.create(Arrays.asList("Logistic regression models are neat".split(" ")))
);
StructType schema = new StructType(new StructField[]{
new StructField("text", new ArrayType(DataTypes.StringType, true), false, Metadata.empty())
});
Dataset<Row> documentDF = spark.createDataFrame(data, schema);
// Learn a mapping from words to Vectors.
Word2Vec word2Vec = new Word2Vec()
.setInputCol("text")
.setOutputCol("result")
.setVectorSize(7)
.setMinCount(0);
Word2VecModel model = word2Vec.fit(documentDF);
Dataset<Row> result = model.transform(documentDF);
for (Row row : result.collectAsList()) {
List<String> text = row.getList(0);
System.out.println("Schema: " + row.schema());
Vector vector = (Vector) row.get(1);
System.out.println("Text: " + text + " => \nVector: " + vector + "\n");
}
// $example off$
spark.stop();
}
}
并且它会打印:
Schema: StructType(StructField(text,ArrayType(StringType,true),false), StructField(result,org.apache.spark.ml.linalg.VectorUDT@3bfc3ba7,true))
Text: [Hi, I, heard, about, Spark] =>
Vector: [-0.0033279924420639875,-0.0024428479373455048,0.01406305879354477,0.030621735751628878,0.00792500376701355,0.02839711122214794,-0.02286271695047617]
Schema: StructType(StructField(text,ArrayType(StringType,true),false), StructField(result,org.apache.spark.ml.linalg.VectorUDT@3bfc3ba7,true))
Text: [I, wish, Java, could, use, case, classes] =>
Vector: [-9.96453288410391E-4,-0.013741840076233658,0.013064394239336252,-0.01155538750546319,-0.010510949650779366,0.004538436819400106,-0.0036846946126648356]
Schema: StructType(StructField(text,ArrayType(StringType,true),false), StructField(result,org.apache.spark.ml.linalg.VectorUDT@3bfc3ba7,true))
Text: [Logistic, regression, models, are, neat] =>
Vector: [0.012510885251685977,-0.014472834207117558,0.002779599279165268,0.0022389178164303304,0.012743516173213721,-0.02409198731184006,0.017409833287820222]
如果我说错了,请纠正我,但输入是一个字符串数组,输出是一个单一的向量。而我期望每个单词都被映射成一个向量。