背景: 集群配置如下:
- 所有内容都在Docker文件中运行。
- node1:Spark主节点
- node2:Jupyter Hub(我也在此运行笔记本)
- node3-7:Spark工作节点
- 我可以使用Spark的默认端口从我的工作节点telnet和ping到node2,反之亦然。
问题: 我正在尝试在Pyspark Jupyter笔记本中创建一个以集群部署模式运行的Spark会话。我希望让驱动程序在不是运行Jupyter笔记本的节点上运行。目前,我只能在node2上运行驱动程序才能在集群上运行作业。
经过大量挖掘,我发现了这个stackoverflow帖子,它声称如果您使用Spark运行交互式shell,则只能在本地部署模式下(其中驱动程序位于您正在使用的计算机上)。该帖子继续说,类似于Jupyter Hub的结果也无法在集群部署模式下工作,但我找不到任何可以证实这一点的文档。有人能否确认Jupyter Hub是否可以在任何情况下以集群模式运行?
我尝试以集群部署模式运行Spark会话的尝试:
from pyspark.sql import SparkSession
spark = SparkSession.builder\
.enableHiveSupport()\
.config("spark.local.ip",<node 3 ip>)\
.config("spark.driver.host",<node 3 ip>)\
.config('spark.submit.deployMode','cluster')\
.getOrCreate()
错误:
/usr/spark/python/pyspark/sql/session.py in getOrCreate(self)
167 for key, value in self._options.items():
168 sparkConf.set(key, value)
--> 169 sc = SparkContext.getOrCreate(sparkConf)
170 # This SparkContext may be an existing one.
171 for key, value in self._options.items():
/usr/spark/python/pyspark/context.py in getOrCreate(cls, conf)
308 with SparkContext._lock:
309 if SparkContext._active_spark_context is None:
--> 310 SparkContext(conf=conf or SparkConf())
311 return SparkContext._active_spark_context
312
/usr/spark/python/pyspark/context.py in __init__(self, master, appName, sparkHome, pyFiles, environment, batchSize, serializer, conf, gateway, jsc, profiler_cls)
113 """
114 self._callsite = first_spark_call() or CallSite(None, None, None)
--> 115 SparkContext._ensure_initialized(self, gateway=gateway, conf=conf)
116 try:
117 self._do_init(master, appName, sparkHome, pyFiles, environment, batchSize, serializer,
/usr/spark/python/pyspark/context.py in _ensure_initialized(cls, instance, gateway, conf)
257 with SparkContext._lock:
258 if not SparkContext._gateway:
--> 259 SparkContext._gateway = gateway or launch_gateway(conf)
260 SparkContext._jvm = SparkContext._gateway.jvm
261
/usr/spark/python/pyspark/java_gateway.py in launch_gateway(conf)
93 callback_socket.close()
94 if gateway_port is None:
---> 95 raise Exception("Java gateway process exited before sending the driver its port number")
96
97 # In Windows, ensure the Java child processes do not linger after Python has exited.
Exception: Java gateway process exited before sending the driver its port number
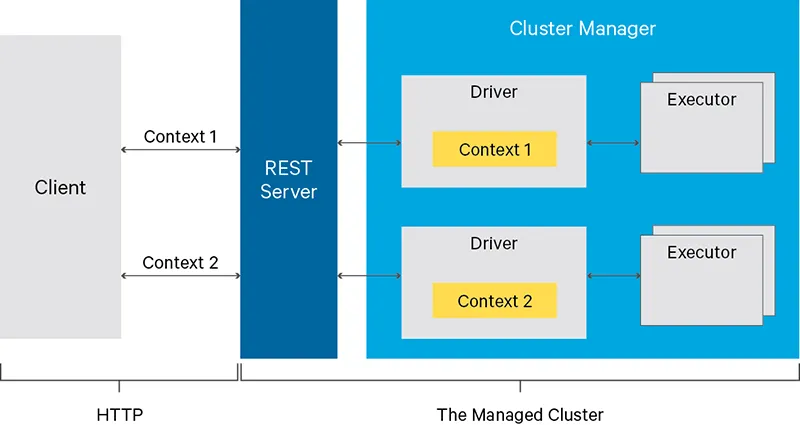
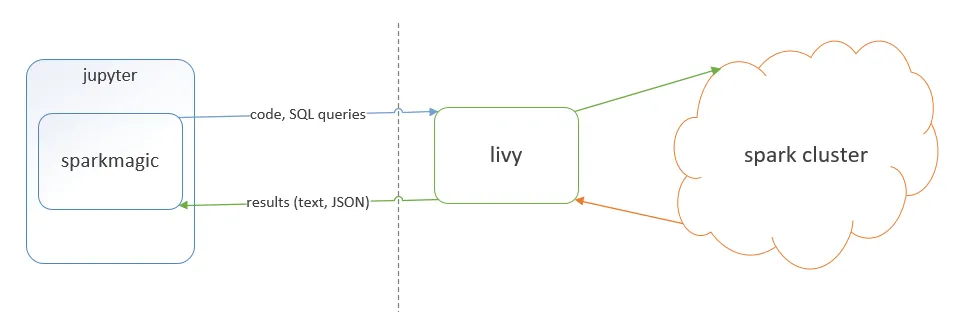
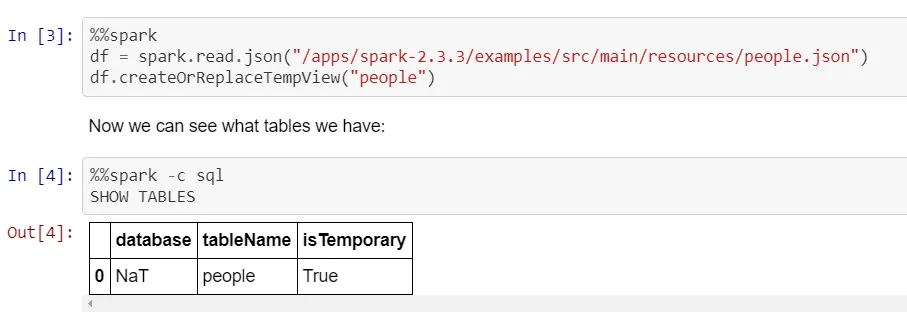
yarn-cluster模式与pyspark。@J Schmidt指出的错误与pyspark在独立模式下运行无关...实际上,他的示例显示了.config('spark.submit.deployMode','cluster'),这不是独立模式。谢谢。 - Tagar