我是一个pandas的初学者,当我对包含datetime64[ns]数据类型列的多个列进行groupby-transform操作时,遇到了非常奇怪的行为。
我的(玩具)示例如下:
import pandas as pd
df = pd.DataFrame({'date': [pd.datetime(2014,3,17), pd.datetime(2014,3,24), pd.datetime(2014,3,17)], 'hdg_id': [4041,4041,4041],'stock': [1.0,1.0,1.0]})
In[117]: df
Out[117]:
date hdg_id stock
0 2014-03-17 4041 1
1 2014-03-24 4041 1
2 2014-03-17 4041 1
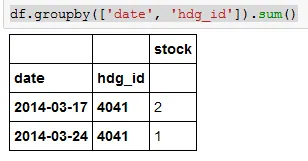
我现在按日期和hdg_id进行分组(对于hdg_id来说,这是微不足道的,因为只有一个唯一值,但是我需要多重分组来产生结果,我的实际应用当然更复杂):
In[118]: df.groupby(['date', 'hdg_id']).transform(sum)
Out[118]:
stock
0 0.000000e+00
1 4.940656e-324
2 0.000000e+00
这不是我期望的结果。如果我将列日期转换为字符串类型,我会得到我想要的结果:
In[129]: df['date']=df['date'].astype(str)
In[131]: df.groupby(['date', 'hdg_id']).transform(sum)
Out[131]:
stock
0 2
1 1
2 2
有人能分享一些正在发生的情况吗?
非常感谢!