我想要实现Logoot,以实现最终收敛的P2P文本编辑。但是我遇到了一些问题。 我对Logoot的理解是,对象(原始论文中的文本行,但可以是字符或单词)之间的间隔可以由于无限的标识符而被无限地分割。这意味着对象的位置不是像WOOT那样由其邻居确定(这将需要墓碑),而是由沿字符串长度的固定数值点确定。结合唯一的站点标识符,这也为我们提供了一个总顺序,并启用了最终收敛。但是...当在同一位置进行并发编辑时,这不会引起问题吗?如果两个断开的客户端从同一光标位置开始编写新句子,然后合并,它们的句子有很大机会交错。下面是我所说的内容的白板示例:
以上只是一个简单的例子,但在更普遍的情况下,想象一下如果两个用户想要在现有的两个句子之间插入不同的句子。如果其中一个用户离线,他们不应该回来看到一堆乱码!显然,为了保持意图,一个句子应该跟随另一个句子。
我在阅读论文时是否漏掉了什么,还是这是Logoot的固有缺陷?
(此外,为什么算法中似乎没有使用记录的时钟值?论文甚至指出,每个对象的标识符在没有时钟的情况下必然是唯一的。)
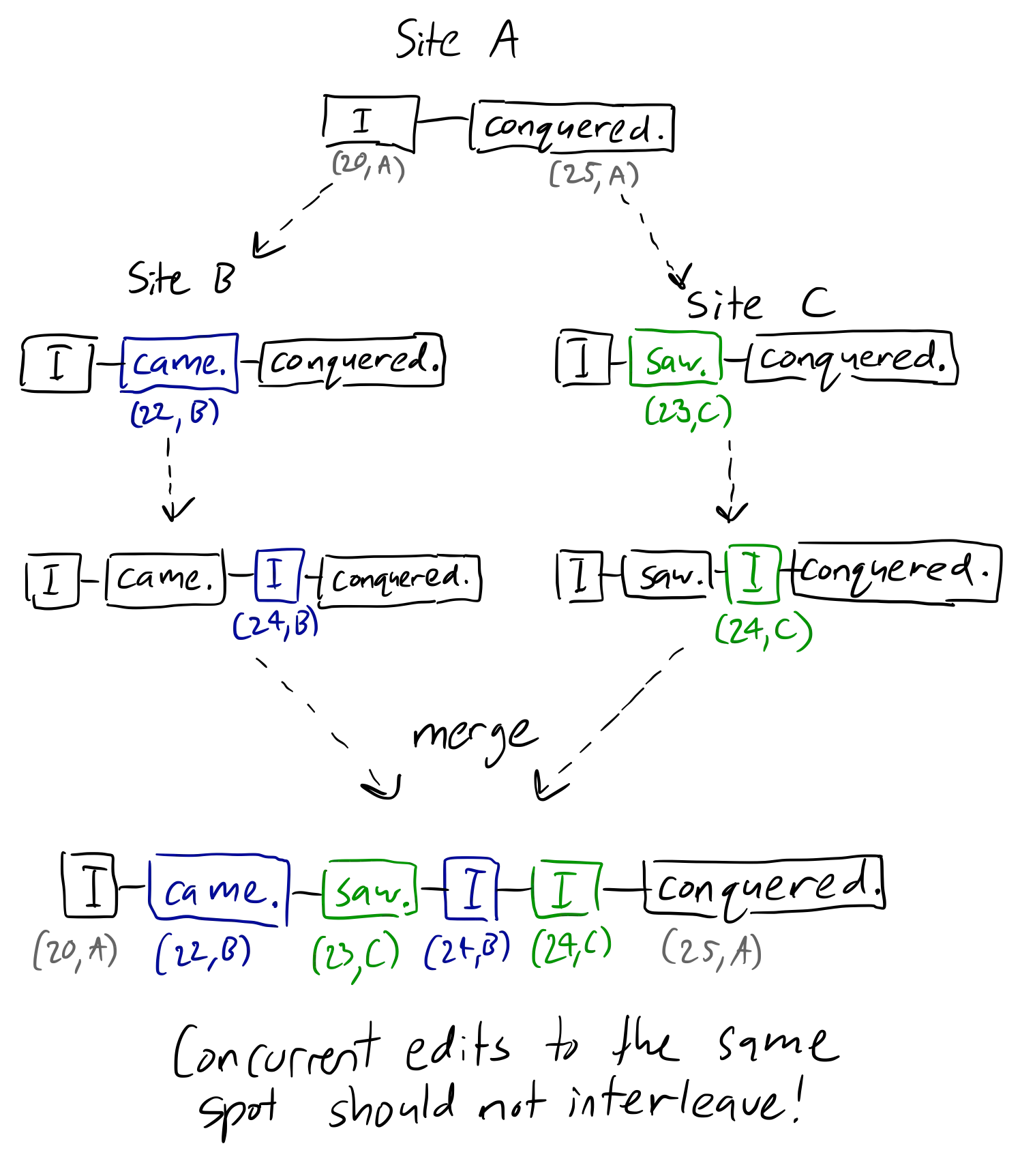
以上只是一个简单的例子,但在更普遍的情况下,想象一下如果两个用户想要在现有的两个句子之间插入不同的句子。如果其中一个用户离线,他们不应该回来看到一堆乱码!显然,为了保持意图,一个句子应该跟随另一个句子。
我在阅读论文时是否漏掉了什么,还是这是Logoot的固有缺陷?
(此外,为什么算法中似乎没有使用记录的时钟值?论文甚至指出,每个对象的标识符在没有时钟的情况下必然是唯一的。)