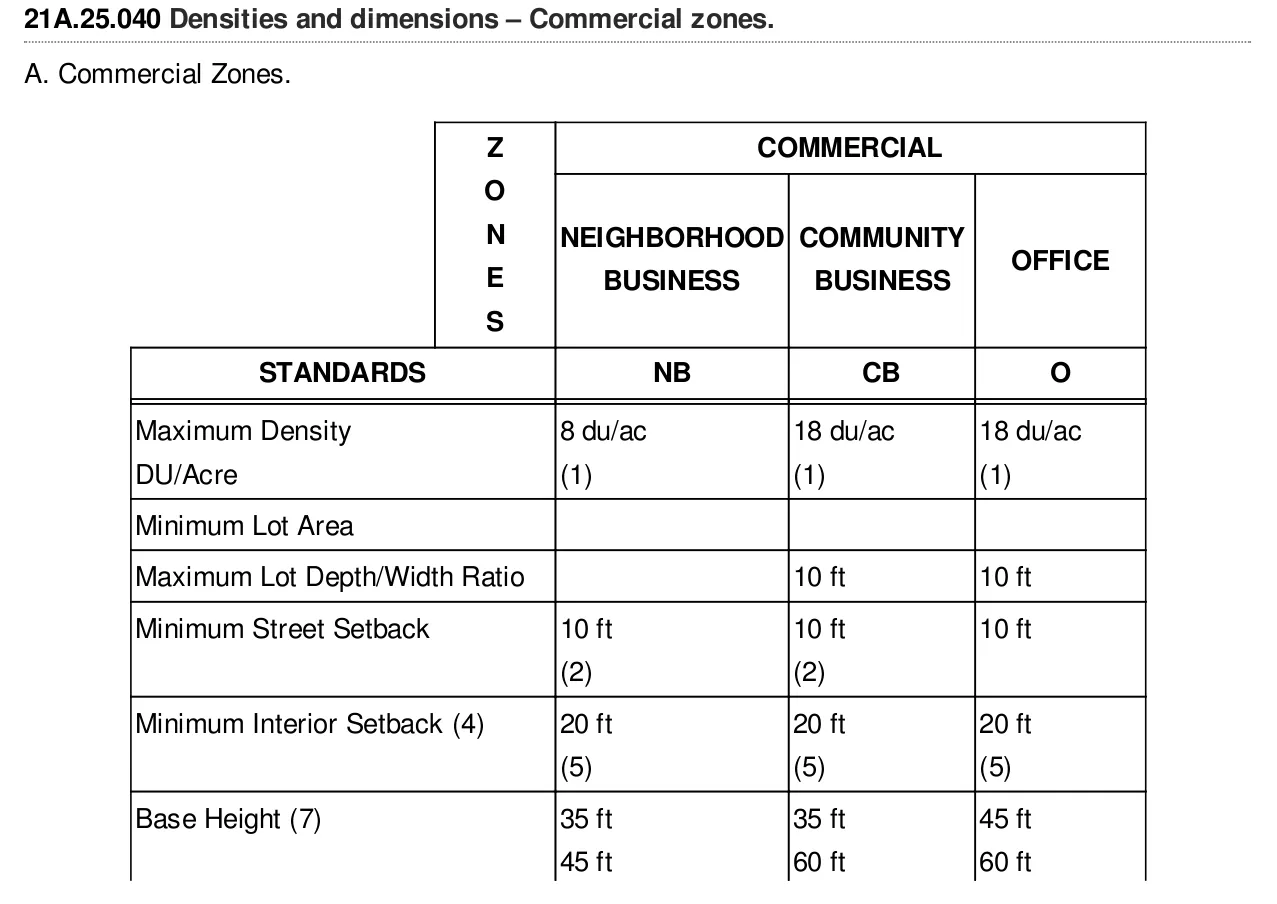
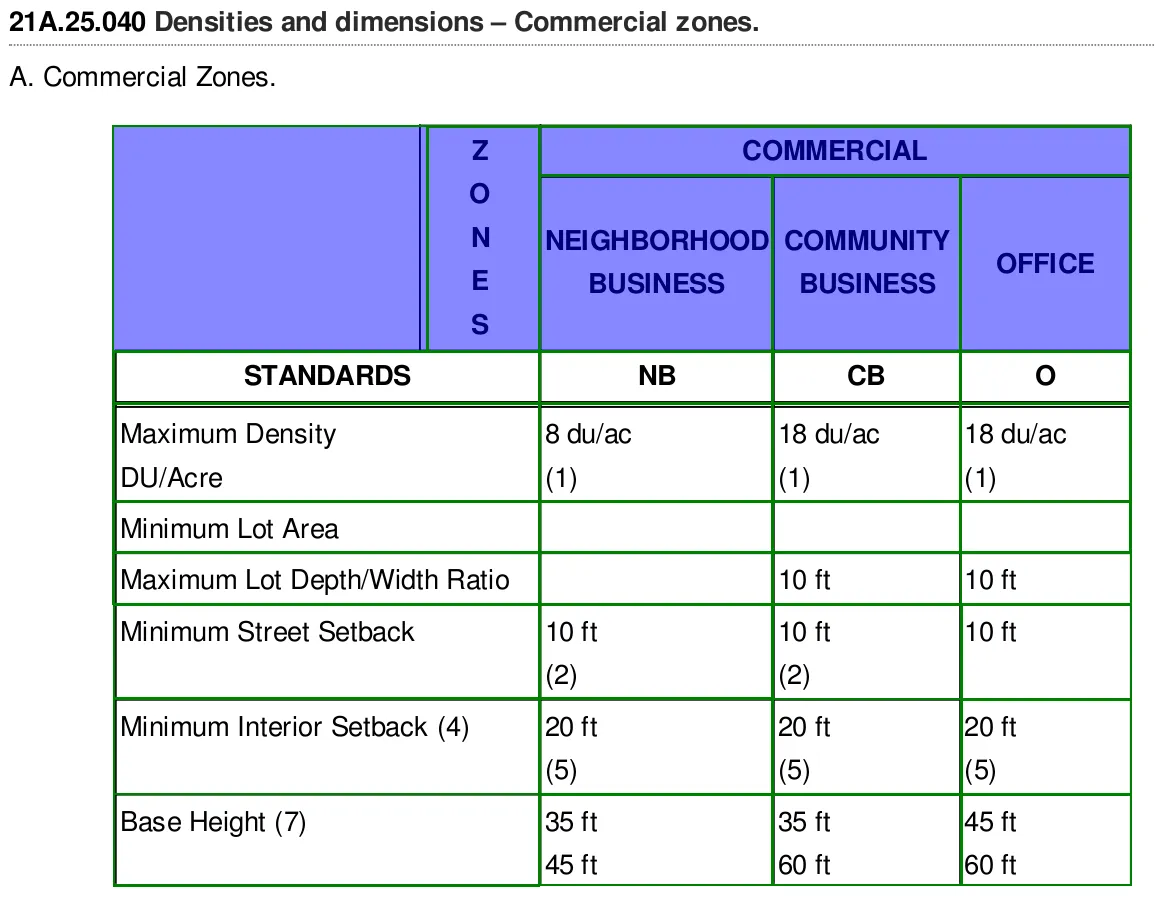
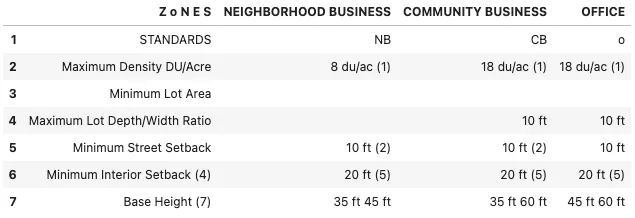
对于遇到包含图像的pdf且需要使用OCR的任何人,本答案提供解决方案。我没有找到可行的现成解决方案,没有给我所需的准确性。
以下是我发现有效的步骤。
使用https://poppler.freedesktop.org/中的pdfimages将pdf的页面转换为图像。
使用Tesseract进行旋转检测,并使用ImageMagick mogrify进行修复。
使用OpenCV查找并提取表格。
使用OpenCV从表格中查找并提取每个单元格。
使用OpenCV裁剪和清除每个单元格,以使OCR软件不会混淆。
使用Tesseract对每个单元格进行OCR。
将每个单元格的提取文本合并到您需要的格式中。
我编写了一个Python软件包,其中包含可以帮助完成这些步骤的模块。
Repo: https://github.com/eihli/image-table-ocr
Docs & Source: https://eihli.github.io/image-table-ocr/pdf_table_extraction_and_ocr.html
其中一些步骤不需要代码,它们利用外部工具如pdfimages和tesseract。我将为那些需要代码的步骤提供一些简要示例。
- 查找表格:
在找到表格的方法时,此链接是一个很好的参考。https://answers.opencv.org/question/63847/how-to-extract-tables-from-an-image/
import cv2
def find_tables(image):
BLUR_KERNEL_SIZE = (17, 17)
STD_DEV_X_DIRECTION = 0
STD_DEV_Y_DIRECTION = 0
blurred = cv2.GaussianBlur(image, BLUR_KERNEL_SIZE, STD_DEV_X_DIRECTION, STD_DEV_Y_DIRECTION)
MAX_COLOR_VAL = 255
BLOCK_SIZE = 15
SUBTRACT_FROM_MEAN = -2
img_bin = cv2.adaptiveThreshold(
~blurred,
MAX_COLOR_VAL,
cv2.ADAPTIVE_THRESH_MEAN_C,
cv2.THRESH_BINARY,
BLOCK_SIZE,
SUBTRACT_FROM_MEAN,
)
vertical = horizontal = img_bin.copy()
SCALE = 5
image_width, image_height = horizontal.shape
horizontal_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (int(image_width / SCALE), 1))
horizontally_opened = cv2.morphologyEx(img_bin, cv2.MORPH_OPEN, horizontal_kernel)
vertical_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (1, int(image_height / SCALE)))
vertically_opened = cv2.morphologyEx(img_bin, cv2.MORPH_OPEN, vertical_kernel)
horizontally_dilated = cv2.dilate(horizontally_opened, cv2.getStructuringElement(cv2.MORPH_RECT, (40, 1)))
vertically_dilated = cv2.dilate(vertically_opened, cv2.getStructuringElement(cv2.MORPH_RECT, (1, 60)))
mask = horizontally_dilated + vertically_dilated
contours, hierarchy = cv2.findContours(
mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE,
)
MIN_TABLE_AREA = 1e5
contours = [c for c in contours if cv2.contourArea(c) > MIN_TABLE_AREA]
perimeter_lengths = [cv2.arcLength(c, True) for c in contours]
epsilons = [0.1 * p for p in perimeter_lengths]
approx_polys = [cv2.approxPolyDP(c, e, True) for c, e in zip(contours, epsilons)]
bounding_rects = [cv2.boundingRect(a) for a in approx_polys]
images = [image[y:y+h, x:x+w] for x, y, w, h in bounding_rects]
return images
- 从表格中提取单元格。
这与第2个问题非常相似,因此我不会包含所有的代码。我参考的部分将在单元格排序中。
我们想要从左到右、从上到下地识别单元格。
我们将找到具有最左上角的矩形。然后,我们将查找所有中心点位于该左上矩形的顶部y坐标和底部y坐标之间的矩形。然后,我们将按其中心点的x值对这些矩形进行排序。我们将从列表中删除这些矩形并重复这个过程。
def cell_in_same_row(c1, c2):
c1_center = c1[1] + c1[3] - c1[3] / 2
c2_bottom = c2[1] + c2[3]
c2_top = c2[1]
return c2_top < c1_center < c2_bottom
orig_cells = [c for c in cells]
rows = []
while cells:
first = cells[0]
rest = cells[1:]
cells_in_same_row = sorted(
[
c for c in rest
if cell_in_same_row(c, first)
],
key=lambda c: c[0]
)
row_cells = sorted([first] + cells_in_same_row, key=lambda c: c[0])
rows.append(row_cells)
cells = [
c for c in rest
if not cell_in_same_row(c, first)
]
def avg_height_of_center(row):
centers = [y + h - h / 2 for x, y, w, h in row]
return sum(centers) / len(centers)
rows.sort(key=avg_height_of_center)