我正在尝试使用Python提取此PDF文件中包含的文本。
我正在使用PyPDF2包(版本1.27.2),并拥有以下脚本:
import PyPDF2
with open("sample.pdf", "rb") as pdf_file:
read_pdf = PyPDF2.PdfFileReader(pdf_file)
number_of_pages = read_pdf.getNumPages()
page = read_pdf.pages[0]
page_content = page.extractText()
print(page_content)
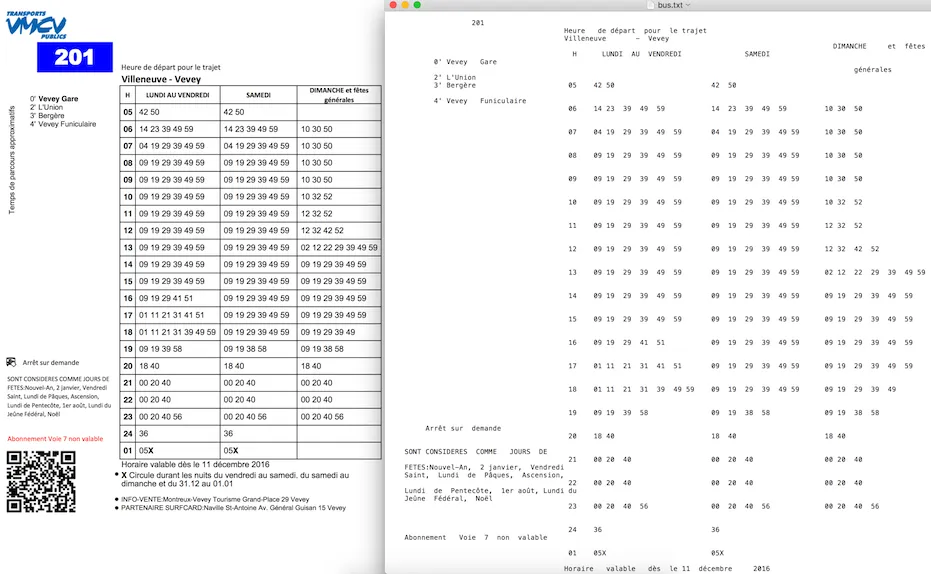
当我运行代码时,我的输出结果与PDF文档中的不同:
! " # $ % # $ % &% $ &' ( ) * % + , - % . / 0 1 ' * 2 3% 4
5
' % 1 $ # 2 6 % 3/ % 7 / ) ) / 8 % &) / 2 6 % 8 # 3" % 3" * % 31 3/ 9 # &)
%
我如何提取PDF文档中原样的文本?