我正在尝试使用Pandas进行分组并应用排序,类似下面的示例:
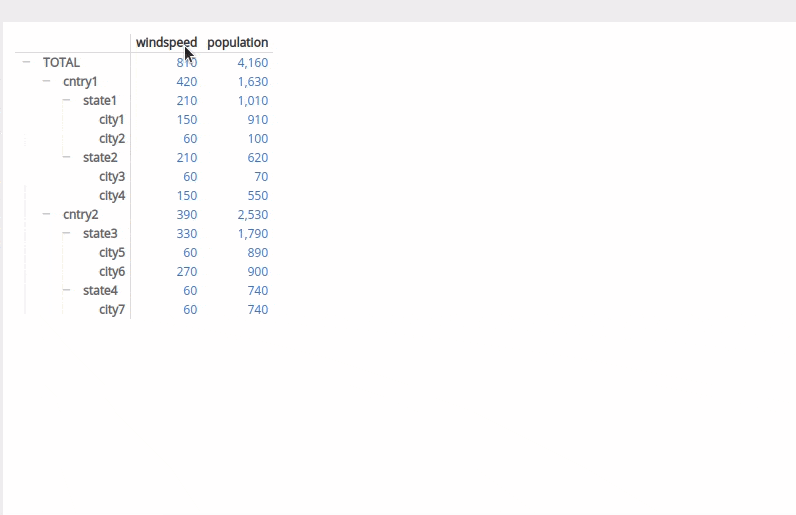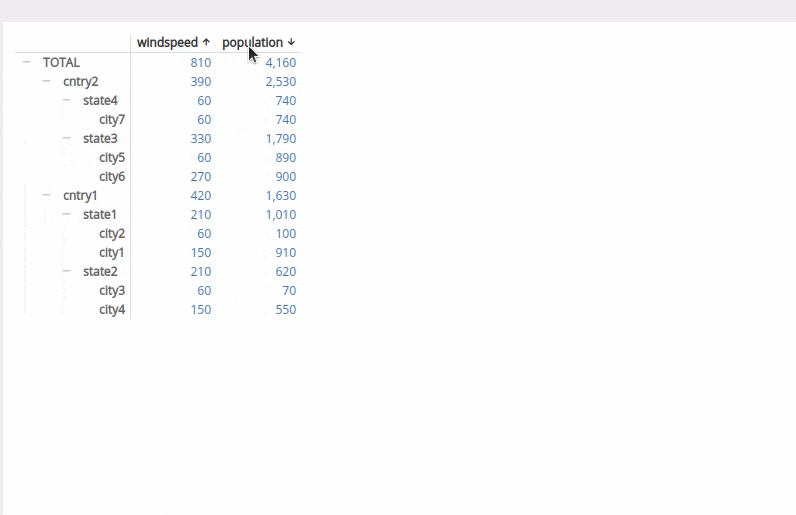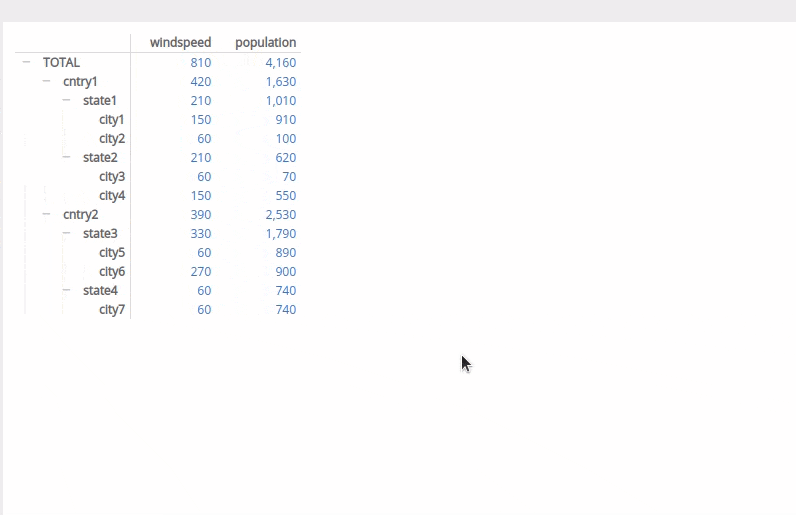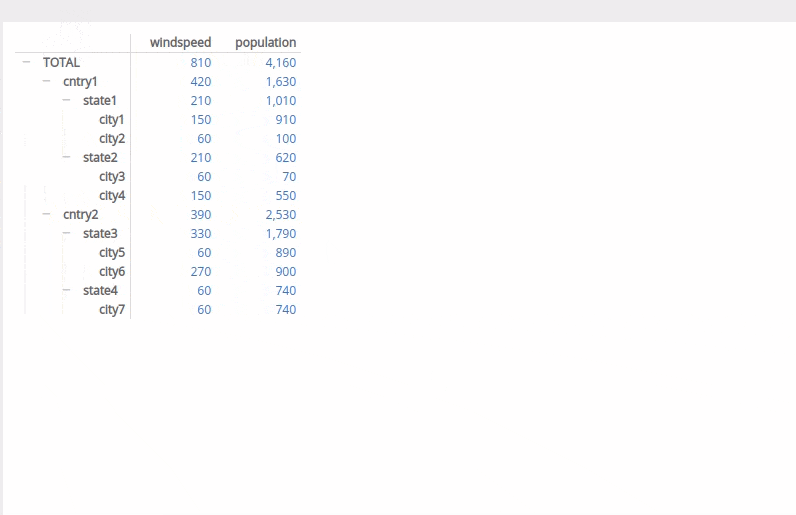
目前我已经创建了各个框架以获取小计。不确定如何继续操作以正确排序而不会借助黑科技。
示例数据框来自此前的问题。
df = pd.DataFrame({
'admin0': ['cntry1', 'cntry1', 'cntry1', 'cntry1', 'cntry1', 'cntry1', 'cntry2', 'cntry2', 'cntry2', 'cntry2', 'cntry2'],
'admin1': ['state1', 'state1', 'state1', 'state2', 'state2', 'state2', 'state3', 'state3', 'state3', 'state3', 'state4'],
'admin2': ['city1', 'city1', 'city2', 'city3', 'city4', 'city4', 'city5', 'city6', 'city6', 'city6', 'city7'],
'windspeed': [60, 90, 60, 60, 60, 90, 60, 60, 90, 120, 60],
'population': [700, 210, 100, 70, 180, 370, 890, 120, 420, 360, 740]
})
g1 = df.groupby(['admin0', 'admin1', 'admin2']).sum()
g2 = g1.groupby(level=[0, 1]).sum()
g2.index = pd.MultiIndex.from_arrays([g2.index.get_level_values(0), g2.index.get_level_values(1), len(g2.index)*['']])
g3 = g1.groupby(level=0).sum()
g3.index = pd.MultiIndex.from_arrays([g3.index.get_level_values(0), len(g3.index)*[''], len(g3.index)*['']])
g = pd.concat([g1, g2, g3])
现在g的状态是:
windspeed population
admin0 admin1 admin2
cntry1 state1 city1 150 910
city2 60 100
state2 city3 60 70
city4 150 550
cntry2 state3 city5 60 890
city6 270 900
state4 city7 60 740
cntry1 state1 210 1010
state2 210 620
cntry2 state3 330 1790
state4 60 740
cntry1 420 1630
cntry2 390 2530
我现在希望可以进行排序,而不改变如gif所示的分组方式。
当按风速升序分组时,预期响应结果为:
windspeed population
admin0 admin1 admin2
cntry2 390 2530
state4 60 740
city7 60 740
state3 330 1790
city5 60 890
city6 270 900
cntry1 420 1630
state1 210 1010
city2 60 100
city1 150 910
state2 210 620
city3 60 70
city4 150 550
g.sort_values('windspeed', ascending=False)?人口也一样吗? - piterbarg