我正在处理带有文本的图像。问题是这些图像是收据,在经过大量转换后,文本失去了质量。我使用Python和OpenCV。我尝试了很多形态学变换的组合,来自形态学变换文档,但我没有得到令人满意的结果。我目前正在进行以下操作(我将注释我尝试过的内容,并让未注释的内容保持不变):
通过这个,从原始图像:
我得到了不错的结果,但如果解决这个问题,结果将更好。也许我可以做另一件事情,或者使用更好的形态学变换组合。如果有其他工具(PIL,imagemagick等),我可以使用它们。
这是整张图片,你可以看到它的样子:
kernel = np.ones((2, 2), np.uint8)
# opening = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel)
# closing = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel)
# dilation = cv2.dilate(opening, kernel, iterations=1)
# kernel = np.ones((3, 3), np.uint8)
erosion = cv2.erode(img, kernel, iterations=1)
# gradient = cv2.morphologyEx(img, cv2.MORPH_GRADIENT, kernel)
#
img = erosion.copy()
通过这个,从原始图像:
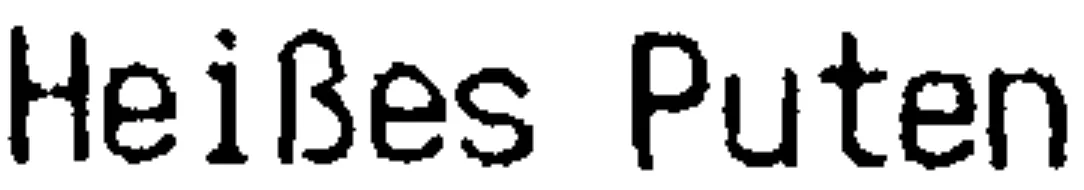

我得到了不错的结果,但如果解决这个问题,结果将更好。也许我可以做另一件事情,或者使用更好的形态学变换组合。如果有其他工具(PIL,imagemagick等),我可以使用它们。
这是整张图片,你可以看到它的样子:
