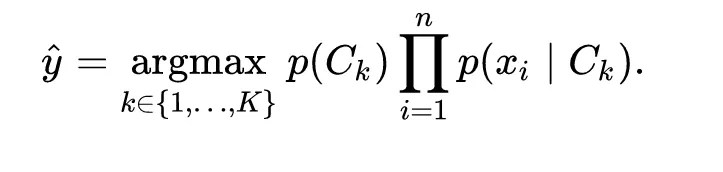我正在使用朴素贝叶斯分类器将几千份文档分为30个不同的类别。我已经实现了一个朴素贝叶斯分类器,并通过一些特征选择(主要是过滤无用单词),在测试数据上获得了约30%的准确率,训练数据上获得了45%的准确率。虽然这比随机结果要好得多,但我希望它能更好。
我尝试过使用AdaBoost与NB一起实现,但似乎没有明显改善结果(相关文献对此存在分歧,有些文章认为AdaBoost与NB并不能给出更好的结果,而有些则认为可以)。您知道是否有其他扩展NB的方法可以可能给出更好的准确度吗?
我正在使用朴素贝叶斯分类器将几千份文档分为30个不同的类别。我已经实现了一个朴素贝叶斯分类器,并通过一些特征选择(主要是过滤无用单词),在测试数据上获得了约30%的准确率,训练数据上获得了45%的准确率。虽然这比随机结果要好得多,但我希望它能更好。
我尝试过使用AdaBoost与NB一起实现,但似乎没有明显改善结果(相关文献对此存在分歧,有些文章认为AdaBoost与NB并不能给出更好的结果,而有些则认为可以)。您知道是否有其他扩展NB的方法可以可能给出更好的准确度吗?
根据我的经验,经过适当的训练,朴素贝叶斯分类器通常非常准确(而且训练速度非常快——比我曾经使用过的任何分类器构建工具都要快得多)。
所以,当你想要提高分类器的预测能力时,可以从以下几个方面入手:
调整分类器参数(调整可调参数);
应用某种分类器组合技术(例如集成、提升或装袋);或者
查看传给分类器的数据——添加更多数据、改进基本解析或者精细选择来自数据的特征。
对于朴素贝叶斯分类器,参数调整是有限的;我建议专注于您的数据——即预处理的质量和特征选择。
I. 数据解析(预处理)
我假设您的原始数据是每个数据点的原始文本字符串,通过一系列处理步骤,您将每个字符串转换为一个结构化向量(1D数组),使每个偏移量对应一个特征(通常是一个单词),在该偏移量中的值对应于该特征出现的频率。
词干提取:手动或使用词干库?流行的开源词干库有 Porter、Lancaster 和 Snowball。因此,例如,如果在给定数据点中有术语程序员,程序,编程,已编程,则词干提取器将把它们缩减为一个词干(可能是程序),因此该数据点的术语向量将具有特征程序的值4,这可能是您想要的。
同义词查找:与词干提取相同的思路——将相关词汇合并成一个词;因此,同义词查找可以将开发人员、程序员、编码器和软件工程师识别并组合成一个术语。
中性词汇:在各个类别中具有类似频率的词汇不适于成为特征。
II. 特征选择
考虑NBC的一个典型用例:过滤垃圾邮件;您可以快速看到它的失败之处,同样快速地看到如何改进它。例如,高于平均水平的垃圾邮件过滤器具有微妙的特征,如:全部大写单词的频率、标题中单词的频率以及标题中感叹号的出现。此外,最好的特征通常不是单个单词,而是诸如单词对或更大的词组等。
III. 特定分类器优化
使用'一对多'方案代替30类——换句话说,您从两类分类器(A类和'其他所有')开始,然后将“其他所有”类别的结果返回给算法进行B类和“其他所有”类别的分类等等。
Fisher方法(可能是优化朴素贝叶斯分类器最常见的方法)。对我来说,我认为Fisher是将输入概率进行标准化(更正确地说是规范化)。NBC使用特征概率构建一个“整篇文档”的概率。 Fisher方法计算每个文档特征的类别概率,然后组合这些特征概率并将组合概率与随机特征集的概率进行比较。
我通常看到在文本分类问题中,训练一对多的SVM或逻辑回归比NB表现更好。正如您可以在这篇由斯坦福人写的不错的文章中看到,对于较长的文档,SVM优于NB。使用SVM和NB(NBSVM)的论文代码在这里。
第二个是调整您的TFIDF公式(例如,子线性tf,smooth_idf)。
规范化您的样本,采用l2或l1规范化(Tfidfvectorization中的默认值),因为它可以补偿不同的文档长度。
多层感知机通常比NB或SVM获得更好的结果,因为引入了内在于许多文本分类问题的非线性。我使用Theano / Lasagne实现了一个高度并行的多层感知机,易于使用和可下载,请点击此处。
尝试调整您的l1 / l2 / elasticnet正则化。这在SGDClassifier / SVM / Logistic Regression中会产生很大的差异。
尝试使用可以在tfidfvectorizer中配置的n-grams。
如果您的文档具有结构(例如,具有标题),请考虑为不同的部分使用不同的特征。例如,如果单词1出现在文档的标题中,请将title_word1添加到您的文档中。
考虑使用文档长度作为特征(例如,单词或字符数)。
考虑使用关于文档的元信息(例如,创建时间,作者名称,文档的URL等)。
最近,Facebook发布了他们的FastText分类代码,在许多任务中表现非常好,一定要尝试。
使用拉普拉斯校正和AdaBoost。
在AdaBoost中,首先为训练数据集中的每个数据元组分配权重。使用init_weights方法设置初始权重,该方法将每个权重初始化为1/d,其中d是训练数据集的大小。
然后,调用generate_classifiers方法,运行k次,创建k个朴素贝叶斯分类器的实例。然后对这些分类器进行加权,并在每个分类器上运行测试数据。分类器的加权“投票”之和构成最终分类。
我们将概率空间更改为对数概率空间,因为我们通过乘法计算概率,结果会非常小。当我们更改为对数概率特征时,我们可以解决欠拟合问题。
朴素贝叶斯基于独立性假设工作,当特征之间存在相关性时,即一个特征依赖于其他特征时,我们的假设将失败。 有关相关性的更多信息可以在这里找到。