"Asymptotic complexity(即大O和大Theta所代表的内容)完全忽略了涉及到的常数因子-它只是旨在提供输入大小增加时运行时间如何变化的指示。"
"因此,一个Θ(n)算法可能比一个Θ(n²)算法在某些给定的n下需要更长的时间-这将取决于所涉及的算法-对于您的特定示例,这将在n < 100的情况下发生,忽略两者之间优化差异的可能性。"
"对于任何两个给定的算法,分别采用Θ(n)和Θ(n²)时间,你可能会看到以下情况之一:"
- 当
n 很小时,Θ(n) 算法比 Θ(n2) 算法更慢,当 n 增加时,Θ(n) 算法变得更慢(如果 Θ(n) 算法更复杂,即具有更高的常数因子),或者
Θ(n2) 算法总是更慢。
尽管 Θ(n) 算法可能会在某些情况下比 Θ(n2) 算法更慢,然后又比 Θ(n) 算法更快,以此类推,直到 n 变得非常大,从那时起,Θ(n2) 算法将永远更慢,尽管这种情况发生的可能性很小。
稍微更数学化一点:
假设 Θ(n2) 算法需要进行 cn2 次操作,其中 c 是某个常数。
而 Θ(n) 算法需要进行 dn 次操作,其中 d 是某个常数。
这符合正式定义,因为我们可以假设对于大于 0 的 n(即所有 n),运行时间所在的两个函数是相同的。
按照你的例子,如果你说 c = 1 和 d = 100,则当 n = 100 时,Θ(n2) 算法会变慢,此前 Θ(n) 算法会更慢。
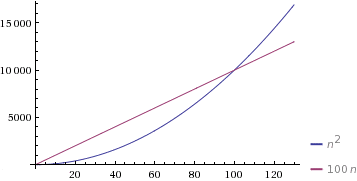
(由WolframAlpha提供).
符号说明:
严格来说,大O表示的只是一个上界,这意味着你可以说一个O(1)算法(或者任何时间复杂度小于O(n2)的算法)也需要O(n2)的时间。因此,我使用了大Theta(Θ)符号,它表示紧密的上下界。更多信息请参见正式定义。
通常情况下,大O符号被非正式地视为或教授为紧密的上下界,因此您可能已经在不知道的情况下使用了大Theta符号。
如果我们只讨论上限(根据 big-O 的正式定义),那么情况将会是“任何情况都可以”——
O(n) 和
O(n2) 两者都可能更快,或者它们需要相同数量的时间(渐进地)——通常无法从比较算法的 big-O 中得出特别有意义的结论,我们只能说,对于某个算法的 big-O,该算法的运行时间不会超过那个数量级(渐进地)。请保留 HTML 标签。
c*n步才能完成,其中c是某个常数。因此,无论你在第一个循环中进行了多少次恒定迭代,你的算法仍然是 O(n)。 - ChronoTrigger