我想将Excel表格读入Pandas DataFrame。然而,其中有合并的Excel单元格以及空行(完整/部分填充
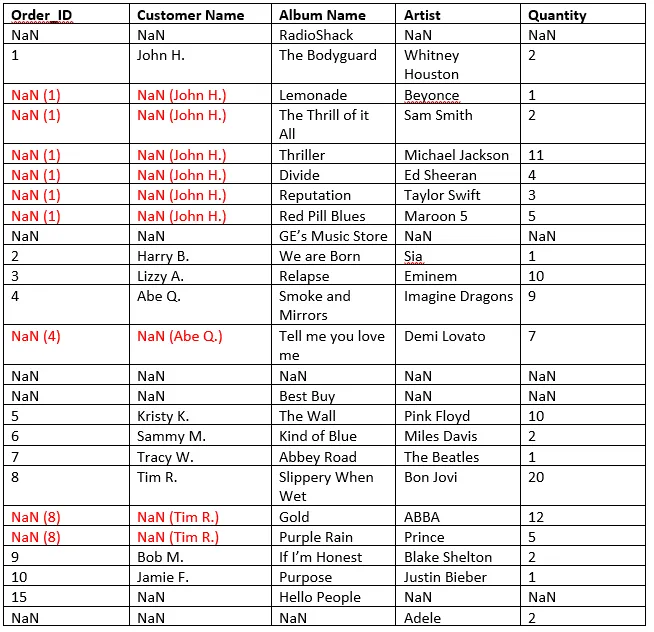
编辑: 我尝试使用以下方法向前填充NaN值:(Pandas:读取带有合并单元格的Excel)
然而,{{NaN}} 值仍然存在。我应该使用什么策略或方法来正确填充 DataFrame?是否有 Pandas 方法可以取消合并单元格并复制相应的内容?
NaN),如下所示。为了澄清,John H.已经下订单购买从"The Bodyguard"到"Red Pill Blues"所有专辑。
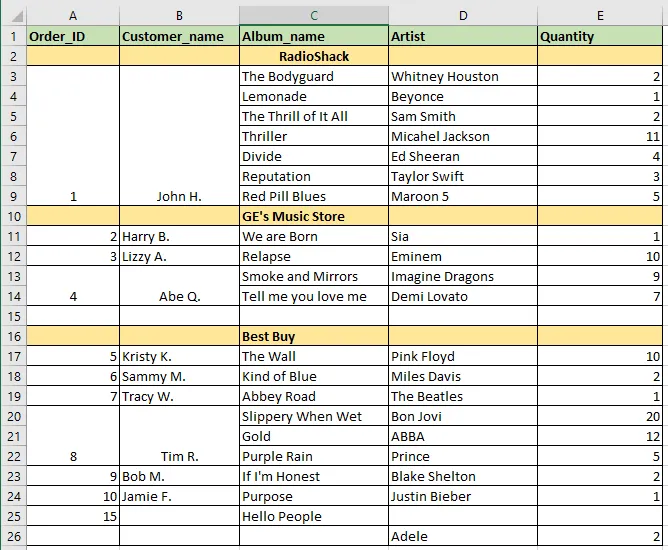
Artist列的值。
编辑: 我尝试使用以下方法向前填充NaN值:(Pandas:读取带有合并单元格的Excel)
df.index = pd.Series(df.index).fillna(method='ffill')
然而,{{NaN}} 值仍然存在。我应该使用什么策略或方法来正确填充 DataFrame?是否有 Pandas 方法可以取消合并单元格并复制相应的内容?
NaN值仍然存在。 - CPU