sigmoid函数定义为
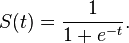
我发现使用C内置函数exp()计算f(x)的值很慢。是否有更快的算法来计算f(x)的值呢?
sigmoid函数定义为
我发现使用C内置函数exp()计算f(x)的值很慢。是否有更快的算法来计算f(x)的值呢?
在神经网络算法中,您不必使用实际的、精确的sigmoid函数,而可以使用一个近似的版本来代替它,这个近似版本具有类似的属性,但计算速度更快。
例如,您可以使用“快速sigmoid”函数。
f(x) = x / (1 + abs(x))
如果f(x)的参数不接近零,使用exp(x)级数展开的前几项不能提供太多帮助;如果参数较大,则使用sigmoid函数级数展开也会遇到同样的问题。
另一种方法是使用表查找。也就是说,您可以预先计算给定数量数据点的sigmoid函数值,然后在它们之间进行快速(线性)插值。
首先我们建议在您的硬件上进行测量。只需运行脚本进行快速基准测试,就可以看到在我的机器上,1/(1+|x|) 是最快的,而 tanh(x) 则是第二快的。误差函数 erf 也非常快。
% gcc -Wall -O2 -lm -o sigmoid-bench{,.c} -std=c99 && ./sigmoid-bench
atan(pi*x/2)*2/pi 24.1 ns
atan(x) 23.0 ns
1/(1+exp(-x)) 20.4 ns
1/sqrt(1+x^2) 13.4 ns
erf(sqrt(pi)*x/2) 6.7 ns
tanh(x) 5.5 ns
x/(1+|x|) 5.5 ns
我希望您知道,具体的结果取决于架构和使用的编译器,但是erf(x)(自C99起),tanh(x)和x/(1.0+fabs(x))可能会是运行速度较快的函数。
x/sqrt(1+x^2) 而不是 1/sqrt(1+x^2)。 - pqn人们关心的大多是一个函数相对于另一个函数有多快,并创建微基准来查看f1(x)是否比f2(x)运行0.0001毫秒更快。但这主要是无关紧要的,因为重要的是网络学习速度以及激活函数试图最小化成本函数所需的速度。
根据当前理论,整流器函数和softplus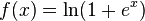
与sigmoid函数或类似的激活函数相比,允许在大型和复杂数据集上更快且有效地训练深层神经结构。
因此,我建议抛弃微观优化,看看哪个函数能够更快地学习(还要考虑各种其他成本函数)。
为了使神经网络更加灵活,通常使用一些alpha值来改变图形在0处的角度。
Sigmoid函数长这样:
f(x) = 1 / ( 1+exp(-x*alpha))
f(x) = 0.5 * (x * alpha / (1 + abs(x*alpha))) + 0.5
您可以在这里查看图形。
当我使用绝对值函数时,网络速度提高了100多倍。
x/sqrt(1+x^2)是迄今为止速度最快的函数。
例如,使用单精度浮点内置函数:
__device__ void fooCudaKernel(/* some arguments */) {
float foo, sigmoid;
// some code defining foo
sigmoid = __fmul_rz(rsqrtf(__fmaf_rz(foo,foo,1)),foo);
}
此外,您可以使用sigmoid的粗略版本(其与原始版本的差异不大于0.2%):
inline float RoughSigmoid(float value)
{
float x = ::abs(value);
float x2 = x*x;
float e = 1.0f + x + x2*0.555f + x2*x2*0.143f;
return 1.0f / (1.0f + (value > 0 ? 1.0f / e : e));
}
void RoughSigmoid(const float * src, size_t size, const float * slope, float * dst)
{
float s = slope[0];
for (size_t i = 0; i < size; ++i)
dst[i] = RoughSigmoid(src[i] * s);
}
使用SSE来优化RoughSigmoid函数:
#include <xmmintrin.h>
void RoughSigmoid(const float * src, size_t size, const float * slope, float * dst)
{
size_t alignedSize = size/4*4;
__m128 _slope = _mm_set1_ps(*slope);
__m128 _0 = _mm_set1_ps(-0.0f);
__m128 _1 = _mm_set1_ps(1.0f);
__m128 _0555 = _mm_set1_ps(0.555f);
__m128 _0143 = _mm_set1_ps(0.143f);
size_t i = 0;
for (; i < alignedSize; i += 4)
{
__m128 _src = _mm_loadu_ps(src + i);
__m128 x = _mm_andnot_ps(_0, _mm_mul_ps(_src, _slope));
__m128 x2 = _mm_mul_ps(x, x);
__m128 x4 = _mm_mul_ps(x2, x2);
__m128 series = _mm_add_ps(_mm_add_ps(_1, x), _mm_add_ps(_mm_mul_ps(x2, _0555), _mm_mul_ps(x4, _0143)));
__m128 mask = _mm_cmpgt_ps(_src, _0);
__m128 exp = _mm_or_ps(_mm_and_ps(_mm_rcp_ps(series), mask), _mm_andnot_ps(mask, series));
__m128 sigmoid = _mm_rcp_ps(_mm_add_ps(_1, exp));
_mm_storeu_ps(dst + i, sigmoid);
}
for (; i < size; ++i)
dst[i] = RoughSigmoid(src[i] * slope[0]);
}
使用AVX优化RoughSigmoid函数:
#include <immintrin.h>
void RoughSigmoid(const float * src, size_t size, const float * slope, float * dst)
{
size_t alignedSize = size/8*8;
__m256 _slope = _mm256_set1_ps(*slope);
__m256 _0 = _mm256_set1_ps(-0.0f);
__m256 _1 = _mm256_set1_ps(1.0f);
__m256 _0555 = _mm256_set1_ps(0.555f);
__m256 _0143 = _mm256_set1_ps(0.143f);
size_t i = 0;
for (; i < alignedSize; i += 8)
{
__m256 _src = _mm256_loadu_ps(src + i);
__m256 x = _mm256_andnot_ps(_0, _mm256_mul_ps(_src, _slope));
__m256 x2 = _mm256_mul_ps(x, x);
__m256 x4 = _mm256_mul_ps(x2, x2);
__m256 series = _mm256_add_ps(_mm256_add_ps(_1, x), _mm256_add_ps(_mm256_mul_ps(x2, _0555), _mm256_mul_ps(x4, _0143)));
__m256 mask = _mm256_cmp_ps(_src, _0, _CMP_GT_OS);
__m256 exp = _mm256_or_ps(_mm256_and_ps(_mm256_rcp_ps(series), mask), _mm256_andnot_ps(mask, series));
__m256 sigmoid = _mm256_rcp_ps(_mm256_add_ps(_1, exp));
_mm256_storeu_ps(dst + i, sigmoid);
}
for (; i < size; ++i)
dst[i] = RoughSigmoid(src[i] * slope[0]);
}
该代码基于 '@jenkas' 先前发布的 C# 版本进行了轻微修改。
下面的 C++ 代码提供了优秀的精度,通过允许编译器将编译后的代码自动向SIMD指令的简单循环中扩展,胜过低精度近似值。GCC会将代码编译为执行四个sigmoid(或tanh)计算的SIMD(Arm Neon或Intel AVX)指令。自动向量化可以获得与非常低精度优化相当的性能,同时保持基本完整的精度。Microsoft和Intel编译器也支持自动向量化。
本文最后提供了有关自动向量化、编译器优化和产生最佳性能的实践的简要讨论。
以下函数相对于 1/(1+exp(-v)) 在全范围内提供最大误差 +/- 6.55651e-07。
// Returns float approximation of 1/(1+exp(-v))
inline float fast_sigmoid(float v)
{
constexpr float c1 = 0.03138777F;
constexpr float c2 = 0.276281267F;
constexpr float c_log2f = 1.442695022F;
v *= c_log2f*0.5;
int intPart = (int)v;
float x = (v - intPart);
float xx = x * x;
float v1 = c_log2f + c2 * xx;
float v2 = x + xx * c1 * x;
float v3 = (v2 + v1);
*((int*)&v3) += intPart << 24;
float v4 = v2 - v1;
float res = v3 / (v3 - v4); //for tanh change to (v3 + v4)/ (v3 - v4)
return res;
}
// Returns float approximation tanh(v)
inline float fast_tanh(float v)
{
const float c1 = 0.03138777F;
const float c2 = 0.276281267F;
const float c_log2f = 1.442695022F;
v *= c_log2f;
int intPart = (int)v;
float x = (v - intPart);
float xx = x * x;
float v1 = c_log2f + c2 * xx;
float v2 = x + xx * c1 * x;
float v3 = (v2 + v1);
*((int*)&v3) += intPart << 24;
float v4 = v2 - v1;
float res = (v3+v4) / (v3 - v4);
return res;
}
Raspberry PI 4 (AARCH64)的基准测试结果:
-- Sigmoid benchmark --------
fast_sigmoid(x) 5.63 ns
fast_tanh(x) 5.89 ns
Vectorized fast_sigmoid(out,in,count) using Neon intrinsics
5.79 ns
atan(pi*/2 * x)/(pi/2) 27.29 ns
atan(x) 24.13 ns
1/(1+exp(-x)) 14.92 ns
1/sqrt(1+x^2) 4.26 ns
(erf(sqrt(pi)/2 *x) 20.62 ns
tanh(x) 20.64 ns
x/(1+|x|) 8.93 ns
x (measures loop overhead) 1.62 ns
x*x (for reference) 1.62 ns
1/(1+x) (for reference) 2.64 ns
Raspberry Pi 4, aarch64 Arm Cortex 72@1.8GHz. GCC 10.2.1
void vec_sigmoid(
int length,
restrict float*output,
restrict float*input,
restrict float *bias)
{
for (int i = 0; i < length; ++i)
{
output[i] = fast_sigmoid(input[i])+bias[i];
}
}
这段代码是基于@jenkas之前发布的C#代码开发的C++版本,进行了调整以返回1/(1+exp(-x))而不是原始代码计算的1/(1+exp(-2*x))。
尝试这个 .NET Core 5+ 实现
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public static unsafe float FastSigmoid(float v)
{
const float c1 = 0.03138777F;
const float c2 = 0.276281267F;
const float c_log2f = 1.442695022F;
v *= c_log2f;
int intPart = (int)v;
float x = (v - intPart);
float xx = x * x;
float v1 = c_log2f + c2 * xx;
float v2 = x + xx * c1 * x;
float v3 = (v2 + v1);
*((int*)&v3) += intPart << 24;
float v4 = v2 - v1;
float res = v3 / (v3 - v4); //for tanh change to (v3 + v4)/ (v3 - v4)
return res;
}
您可以使用两个公式来简单而有效地进行处理:
if x < 0 then f(x) = 1 / (0.5/(1+(x^2)))
if x > 0 then f(x) = 1 / (-0.5/(1+(x^2)))+1
两个Sigmoid函数的图像 {蓝色: (0.5/(1+(x^2))), 黄色: (-0.5/(1+(x^2)))+1}
1/(1 + 0.3678749025^x)是一个很好的逼近方式。它非常接近,只需要通过取反x来摆脱一个运算符。
这里展示的一些其他函数也很有趣,但是幂运算真的那么慢吗?我测试过,它实际上比加法更快,但这可能只是偶然现象。如果是这样,那么它应该和所有其他函数一样快或更快。0.5 + 0.5*tanh(0.5*x)与精度较低的0.5 + 0.5*tanh(n)也可以使用。如果您不在乎将其限制在[0,1]范围内,像sigmoid一样,您可以只剩下常数值。但是这假设双曲正切函数更快。{kind=link}
f(x) = 0.5 * (x / (1 + abs(x)) + 1)来近似提问者的 Sigmoid 函数f(x) = 1 / (1 + exp(-x)),对吗? - Gilfoyle