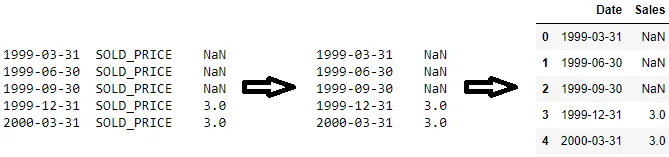
我有一个长这样的Series:
1999-03-31 SOLD_PRICE NaN
1999-06-30 SOLD_PRICE NaN
1999-09-30 SOLD_PRICE NaN
1999-12-31 SOLD_PRICE 3.00
2000-03-31 SOLD_PRICE 3.00
具有类似于以下指数的索引:
MultiIndex
[(1999-03-31 00:00:00, u'SOLD_PRICE'), (1999-06-30 00:00:00, u'SOLD_PRICE'),
(1999-09-30 00:00:00, u'SOLD_PRICE'), (1999-12-31 00:00:00, u'SOLD_PRICE'),...]
我不希望第二列作为索引。理想情况下,我希望有一个DataFrame,其中第一列为“日期”,第二列为“销售”(删除索引的第二级)。我不太清楚如何重新配置索引。
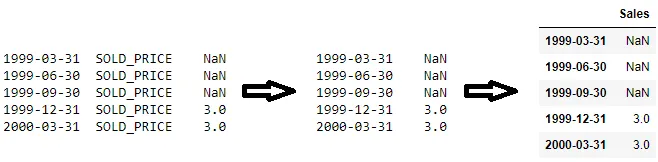
pandas没有DataFrame或Series,而只是称为DataStructure1和DataStructure2,它们的所有方法都被称为method1、method2等等。给你的变量赋予有意义的名称可以使其他人第一次阅读代码时更易理解。给变量赋予有意义的名称还能让你在一个月后重新回到自己的代码并快速上手。 - Phillip Cloud