我有一个像图片中的Pandas数据框。如何将其转换为下面的表格(演示是在Excel中进行的,但我只是想向您说明表格的外观-此问题与从/导入数据框到Excel无关)。
谢谢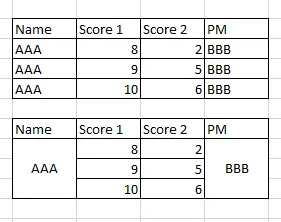
这是不可能的。
pandas.DataFrame对象的底层是numpy数组,它们不会按照您所建议的方式对数据进行分组。因此,任意列不能显示为分组数据。
选项1
可以使用MultiIndex来部分复制所需的输出:
import pandas as pd
df = pd.DataFrame([['AAA', 8, 2, 'BBB'],
['AAA', 9, 5, 'BBB'],
['AAA', 10, 6, 'BBB']],
columns=['Name', 'Score1', 'Score2', 'PM'])
res = df.set_index(['Name', 'PM'])
结果:
Score1 Score2
Name PM
AAA BBB 8 2
BBB 9 5
BBB 10 6
选项2
或者您可以添加一个虚拟列,并在3个列上使用set_index:
df['dummy'] = 0
res = df.set_index(['Name', 'PM', 'dummy'])
结果:
Score1 Score2
Name PM dummy
AAA BBB 0 8 2
0 9 5
0 10 6
你的数据框看起来很好。这取决于你想做什么。
如果你想返回一个Name为AAA且PM为BBB的数据框,你应该使用Pandas查找功能。
dfnew = df[(df.Name == 'AAA') & (df.PM == 'BBB')]
pandas中,你无法像可视化那样获得这些“合并单元格”。据我所知,你不能以你想要的方式从pandas中将输出合并到 Excel 中。那么你究竟在寻找什么? - jpp