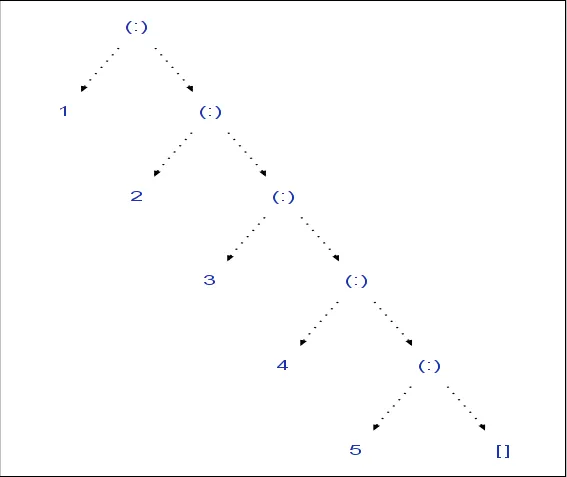
Haskell支持一些基本的列表递归操作,比如
head、tail、init和last。我想知道Haskell是如何表示其列表数据的?如果它是一个单向链表,那么init和last操作可能会随着列表的增长而变得昂贵。如果它是一个双向链表,所有四个操作都可以很容易地实现O(1),但代价是一些内存。无论哪种方式,这对我来说都很重要,这样我就可以编写适当的代码。(尽管函数式编程的精神似乎是“问它做了什么,而不是它是如何做到的”。)