我已经阅读了关于决策函数和score_samples的文档(链接在此),但我无法弄清楚这两种方法之间的区别以及应该在异常值检测算法中使用哪种方法。 欢迎任何帮助。
3个回答
6
请参阅属性
偏移量用于从原始分数定义决策函数。我们有以下关系:
offset_的文档:偏移量用于从原始分数定义决策函数。我们有以下关系:
decision_function = score_samples - offset_。当污染参数设置为“auto”时,偏移量等于-0.5,因为内部点的得分接近0,而异常值的得分接近-1。当提供不同于“auto”的污染参数时,偏移量的定义方式使我们在训练中获得预期数量的异常值(决策函数小于0的样本)。- Ben Reiniger
1
1
正如之前在@Ben Reiniger的答案中所述,
decision_function = score_samples - offset_。为了进一步澄清...
- 如果
contamination = 'auto',那么offset_将固定为0.5 - 如果
contamination设置为其他值,则offset将不再固定。
这可以在源代码的fit函数下看到:
def fit(self, X, y=None, sample_weight=None):
...
if self.contamination == "auto":
# 0.5 plays a special role as described in the original paper.
# we take the opposite as we consider the opposite of their score.
self.offset_ = -0.5
return self
# else, define offset_ wrt contamination parameter
self.offset_ = np.percentile(self.score_samples(X),
100. * self.contamination)
因此,重要的是要注意
contamination 的设置以及您使用的异常分数。 score_samples 返回可以视为“原始”分数,因为它不受 offset_ 的影响,而 decision_function 则取决于 offset_。- Claudio LoBraico
0
用户指南提到了由Fei Tony、Kai Ming和Zhi-Hua撰写的文章孤立森林。
我没有读过这篇论文,但我认为您可以使用任一输出来检测异常值。文档中说score_samples与decision_function相反,所以我认为它们将成反比关系,但两个输出似乎与目标具有完全相同的关系。唯一的区别是它们处于不同的范围内。事实上,它们甚至具有相同的方差。
为了证明这一点,我将模型拟合到sklearn中可用的乳腺癌数据集上,并通过每个输出的十分位数对目标变量进行了分组的平均值进行可视化。正如您所看到的,它们之间确实具有完全相同的关系。
# Import libraries
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import IsolationForest
# Load data
X = load_breast_cancer()['data']
y = load_breast_cancer()['target']
# Fit model
clf = IsolationForest()
clf.fit(X, y)
# Split the outputs into deciles to see their relationship with target
t = pd.DataFrame({'target':y,
'decision_function':clf.decision_function(X),
'score_samples':clf.score_samples(X)})
t['bins_decision_function'] = pd.qcut(t['decision_function'], 10)
t['bins_score_samples'] = pd.qcut(t['score_samples'], 10)
# Visualize relationship
plt.plot(t.groupby('bins_decision_function')['target'].mean().values, lw=3, label='Decision Function')
plt.plot(t.groupby('bins_score_samples')['target'].mean().values, ls='--', label='Score Samples')
plt.legend()
plt.show()
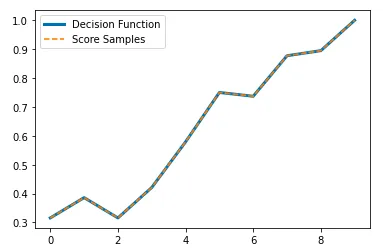
就像我说的那样,它们甚至具有相同的方差:
t[['decision_function','score_samples']].var()
> decision_function 0.003039
> score_samples 0.003039
> dtype: float64
总之,你可以将它们互换使用,因为它们与目标具有相同的关系。
- Arturo Sbr
5
感谢您的详细回复。在您的代码中,t是什么?因为它显示未定义。 - Anne
但是,如果您使用某个介于[0.1, 0.5]之间的数字的污染值而不是“自动”,则会得到与上述方法不同的结果。 - Anne
嗨,安妮。我在我的代码中添加了
t。抱歉我忘记发布那一部分了。你能详细说明一下你最后的评论吗? - Arturo Sbr文档说明
score_samples 是与原始论文的异常分数相反,而不是 sklearn 的 decision_function。 - Ben Reiniger我发现
score_samples返回负值。因此,我认为文档是正确的。为了获得原始分数,我应该执行-clf.score_samples(X)。 - panc网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
-isof.score_samples(X)吗? - panc