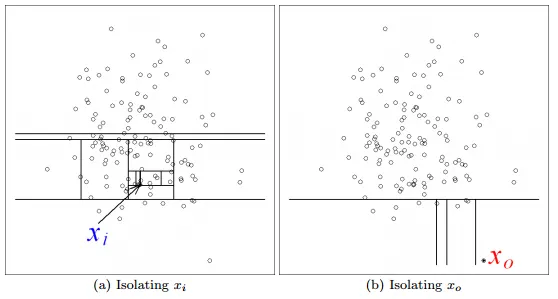
我正在尝试使用Python scikit-learn中的隔离森林算法。 我不明白为什么必须生成
X_test和X_outliers,因为当我获得数据时,我不知道其中是否有异常值。但也许这只是一个例子,并不需要为每种情况生成和填充那些集合。我认为隔离森林不必接收干净的X_train(没有异常值)。我是否误解了该算法?我是否需要使用其他算法(我想到一类支持向量机,但其X_train必须尽可能干净)?隔离森林算法是无监督算法还是监督算法(如随机森林算法)?